
Curve Fitting: Linearization of Nonlinear Relationships
Linearization of Nonlinear Relationships
In the previous two sections, the model function  was formed as a linear combination of functions
was formed as a linear combination of functions  and the minimization of the sum of the squares of the differences between the model prediction and the data produced a linear system of equations to solve for the coefficients in the model. In that case was linear in the coefficients. In certain situations, it is possible to convert nonlinear relationships to a linear form similar to the previous methods. For example, consider the following models
and the minimization of the sum of the squares of the differences between the model prediction and the data produced a linear system of equations to solve for the coefficients in the model. In that case was linear in the coefficients. In certain situations, it is possible to convert nonlinear relationships to a linear form similar to the previous methods. For example, consider the following models  ,
,  , and
, and  :
:
![\[y_{\mbox{exp}}=b_1e^{a_1x}\qquad y_{\mbox{power}}=b_2x^{a_2} \qquad y_{\mbox{log}}=a_3\ln x + b_3\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-2f3527ee2a51cce31563f0462db17131_l3.png "Rendered by QuickLaTeX.com")
is an exponential model, is a power model, while is a logarithmic model. These models are nonlinear in  and the unknown coefficients. However, by taking the natural logarithm of the first two, they can easily be transformed into linear models as follows:
and the unknown coefficients. However, by taking the natural logarithm of the first two, they can easily be transformed into linear models as follows:
![\[\ln y_{\mbox{exp}}=a_1 x+\ln b_1 \qquad \ln y_{\mbox{power}}=a_2 \ln x+\ln b_2\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-58b3803138142c7fcfa0d599e3057b91_l3.png "Rendered by QuickLaTeX.com")
In the first model, the data can be converted to  and linear regression can be used to find the coefficients
and linear regression can be used to find the coefficients  and
and  . For the second model, the data can be converted to
. For the second model, the data can be converted to  and linear regression can be used to find the coefficients
and linear regression can be used to find the coefficients  , and
, and  . The third model can be considered linear after converting the data into the form
. The third model can be considered linear after converting the data into the form  .
.
Coefficient of Determination for Nonlinear Relationships
For nonlinear relationships, the coefficient of determination is not a very good measure for how well the data fit the model. See for example this article on the subject. In fact, different software will give different values for  . We will use the coefficient of determination for nonlinear relationships defined as:
. We will use the coefficient of determination for nonlinear relationships defined as:
![\[R^2=1-\frac{\sum_{i=1}^n\left(y_i-y(x_i)\right)^2}{\sum_{i=1}^n\left(y_i\right)^2}\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-3d8f69fa771439ac80e02380328adf23_l3.png "Rendered by QuickLaTeX.com")
which is equal to 1 minus the ratio between the model sum of squares and the total sum of squares of the data. This is consistent with the definition of used in Mathematica for nonlinear models.
Example 1
Fit an exponential model to the data: (1,1.93),(1.1,1.61),(1.2,2.27),(1.3,3.19),(1.4,3.19),(1.5,3.71),(1.6,4.29),(1.7,4.95),(1.8,6.07),(1.9,7.48),(2,8.72),(2.1,9.34),(2.2,11.62).
Solution
The exponential model has the form:
![\[y_{\mbox{exp}}=b_1e^{a_1x}\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-718d87e6ccd45138ba6d16cf988a7a1b_l3.png "Rendered by QuickLaTeX.com")
This form can be linearized as follows:
![\[\ln y_{\mbox{exp}}=a_1 x+\ln b_1\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-71e58a9f5ea70b6d8c24d6605549aaa2_l3.png "Rendered by QuickLaTeX.com")
The data needs to be converted to .  will be used to designate
will be used to designate  . The following Microsoft Excel table shows the raw data, and after conversion to
. The following Microsoft Excel table shows the raw data, and after conversion to  .
.
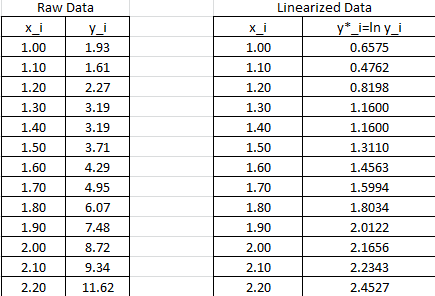
The linear regression described above will be used to find the best fit for the model:
![\[y^*=a^*x+b^*\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-8c7055d378d07ffaf9898e4917fa5ac5_l3.png "Rendered by QuickLaTeX.com")
with
![\[\begin{split}a^*&=\frac{n\sum_{i=1}^nx_iy^*_i-\sum_{i=1}^nx_i\sum_{i=1}^ny^*_i}{n\sum_{i=1}^nx_i^2-\left(\sum_{i=1}^nx_i\right)^2}\\b^*&=\frac{\sum_{i=1}^ny^*_i-a^*\sum_{i=1}^nx_i}{n}\end{split}\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-4454844df4d26460ac458e3771463de2_l3.png "Rendered by QuickLaTeX.com")
The following Microsoft Excel table is used to calculate the various entries in the above equation:
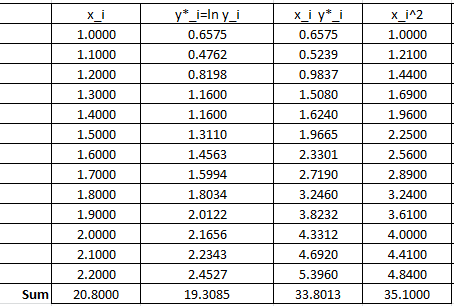
Therefore:
![\[\begin{split}a^*&=\frac{13\times 33.8013-20.8\times 19.3085}{13\times 35.10-\left(20.8\right)^2}=1.5976\\b^*&=\frac{19.3085-1.5976\times 20.8}{13}=-1.0709\end{split}\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-8becaa122aea6f02438419d4931f700c_l3.png "Rendered by QuickLaTeX.com")
These can be used to calculate the coefficients in the original model:
![\[a_1=a^*=1.5976 \qquad b_1=e^{b^*}=e^{-1.0709}=0.3427\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-722e7a0808f528df5375fbaed2220b5f_l3.png "Rendered by QuickLaTeX.com")
Therefore, the best exponential model based on the least squares of the linearized version has the form:
![\[y_{\mbox{exp}}=0.3427e^{1.5976x}\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-63e7a69beee82918a29a4c93a0f8440b_l3.png "Rendered by QuickLaTeX.com")
The following Microsoft Excel chart shows the calculated trendline in Excel with the same coefficients:
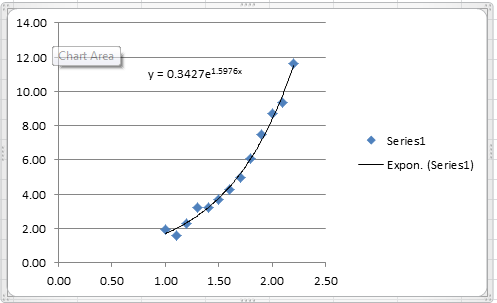
It is possible to calculate the coefficient of determination for the linearized version of this model, however, it would only describe how good the linearized model is. For the nonlinear model, we will use the coefficient of determination as described above which requires the following Microsoft Excel table: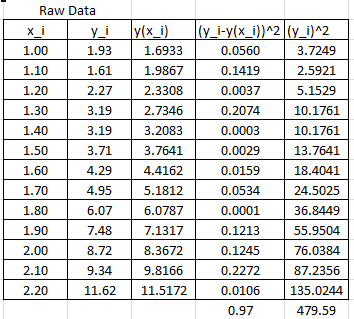
In this case, the coefficient of determination can be calculated as:
![\[R^2=1-\frac{\sum_{i=1}^n\left(y_i-y(x_i)\right)^2}{\sum_{i=1}^n\left(y_i\right)^2}=1-\frac{0.97}{479.59}=0.998\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-b5a6fc36966fc503236190d94216b2fc_l3.png "Rendered by QuickLaTeX.com")
The NonlinearModelFit built-in function in Mathematica can be used to generate the model and calculate its as shown in the code below.
Data = {{1, 1.93}, {1.1, 1.61}, {1.2, 2.27}, {1.3, 3.19}, {1.4, 3.19}, {1.5, 3.71}, {1.6, 4.29}, {1.7, 4.95}, {1.8, 6.07}, {1.9, 7.48}, {2, 8.72}, {2.1, 9.34}, {2.2, 11.62}};
model = NonlinearModelFit[Data, b1*E^(a1*x), {a1, b1}, x]
y = Normal[model]
R2 = model["RSquared"]
Plot[y, {x, 1, 2.2}, Epilog -> {PointSize[Large], Point[Data]}, PlotLegends -> {"Model"}, AxesLabel -> {"x", "y"}, AxesOrigin -> {0, 0} ]
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
Data = [[1, 1.93], [1.1, 1.61], [1.2, 2.27], [1.3, 3.19], [1.4, 3.19], [1.5, 3.71], [1.6, 4.29], [1.7, 4.95], [1.8, 6.07], [1.9, 7.48], [2, 8.72], [2.1, 9.34], [2.2, 11.62]]
def f(x, a, b): return a*np.exp(b*x)
coeff, covariance = curve_fit(f, [point[0] for point in Data],
[point[1] for point in Data])
print("coeff: ",coeff)
x_val = np.arange(1,2.2,0.01)
plt.title('%.5fe**(%.5fx)' % tuple(coeff))
plt.plot(x_val, f(x_val, coeff[0], coeff[1]))
plt.scatter([point[0] for point in Data], [point[1] for point in Data], c='k')
plt.xlabel("x"); plt.ylabel("y")
plt.grid(); plt.show()
# R squared
x = np.array([point[0] for point in Data])
y = np.array([point[1] for point in Data])
y_fit = f(x, coeff[0], coeff[1])
ss_res = np.sum((y - y_fit)**2)
ss_tot = np.sum((y - np.mean(y))**2)
r2 = 1 - (ss_res / ss_tot)
print("R Squared: ",r2)
The following link provides the MATLAB codes for implementing the Linearization of nonlinear exponential model.
Example 2
Fit a power model to the data: (1,1.93),(1.1,1.61),(1.2,2.27),(1.3,3.19),(1.4,3.19),(1.5,3.71),(1.6,4.29),(1.7,4.95),(1.8,6.07),(1.9,7.48),(2,8.72),(2.1,9.34),(2.2,11.62).
Solution
The power model has the form:
![\[y_{\mbox{power}}=b_2x^{a_2}\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-7ab756d4b1bf85d8ea0801d1835ee6b9_l3.png "Rendered by QuickLaTeX.com")
This form can be linearized as follows:
![\[\ln y_{\mbox{power}}=a_2 \ln x+\ln b_2\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-85b9fa1a37831d7d58c006314e711c7e_l3.png "Rendered by QuickLaTeX.com")
The data needs to be converted to . and  will be used to designate and
will be used to designate and  respectively. The following Microsoft Excel table shows the raw data, and after conversion to
respectively. The following Microsoft Excel table shows the raw data, and after conversion to  .
.
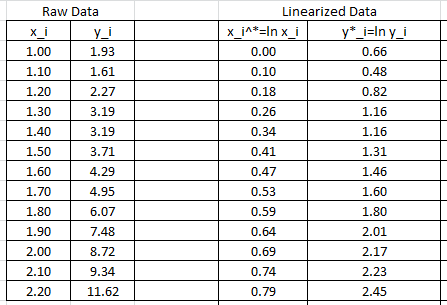
The linear regression described above will be used to find the best fit for the model:
![\[y^*=a^*x^*+b^*\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-279557fd310d83ce4a432828c2a7f7d3_l3.png "Rendered by QuickLaTeX.com")
with
![\[\begin{split}a^*&=\frac{n\sum_{i=1}^nx_i^*y^*_i-\sum_{i=1}^nx_i^*\sum_{i=1}^ny^*_i}{n\sum_{i=1}^n(x_i^*)^2-\left(\sum_{i=1}^nx_i^*\right)^2}\\b^*&=\frac{\sum_{i=1}^ny^*_i-a^*\sum_{i=1}^nx_i^*}{n}\end{split}\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-8d1ddaba26cba0cdea7f406f7c98a6ad_l3.png "Rendered by QuickLaTeX.com")
The following Microsoft Excel table is used to calculate the various entries in the above equation:
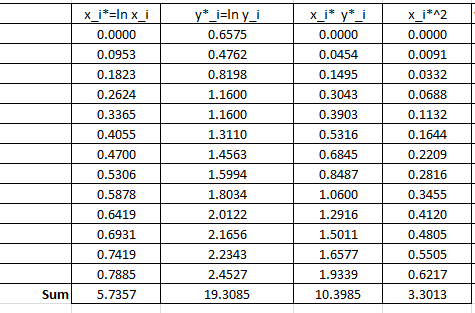
Therefore:
![\[\begin{split}a^*&=\frac{13\times 10.3985-5.7357\times 19.3085}{13\times 3.3013-\left(5.7357\right)^2}=2.4387\\b^*&=\frac{19.3085-2.4387\times 5.7357}{13}=0.4093\end{split}\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-3890aae29708ed93b655b772b816e4b3_l3.png "Rendered by QuickLaTeX.com")
These can be used to calculate the coefficients in the original model:
![\[a_2=a^*=2.4387 \qquad b_2=e^{b^*}=e^{0.4093}=1.5058\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ff5ca93cf8e6339c76d11f2c694f06ae_l3.png "Rendered by QuickLaTeX.com")
Therefore, the best power model based on the least squares of the linearized version has the form:
![\[y_{\mbox{power}}=1.5058x^{2.4387}\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-40dd4fe320b44783a18be1f1d8ef649c_l3.png "Rendered by QuickLaTeX.com")
The following Microsoft Excel chart shows the calculated trendline in Excel with the same coefficients:
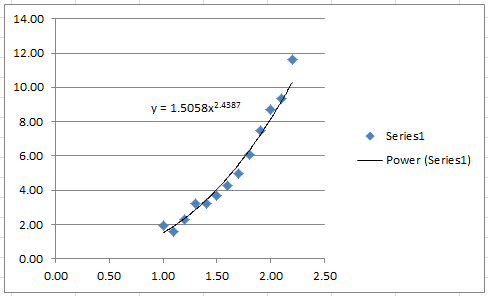
It is possible to calculate the coefficient of determination for the linearized version of this model, however, it would only describe how good the linearized model is. For the nonlinear model, we will use the coefficient of determination as described above which requires the following Microsoft Excel table: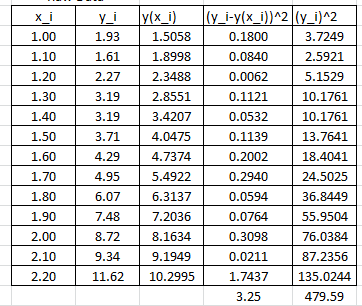
In this case, the coefficient of determination can be calculated as:
![\[R^2=1-\frac{\sum_{i=1}^n\left(y_i-y(x_i)\right)^2}{\sum_{i=1}^n\left(y_i\right)^2}=1-\frac{3.25}{479.59}=0.9932\]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-0df28b96159293ab27023e6fd242c6ed_l3.png "Rendered by QuickLaTeX.com")
The NonlinearModelFit built-in function in Mathematica can be used to generate a slightly better model with a higher . The following is the corresponding Mathematica output.
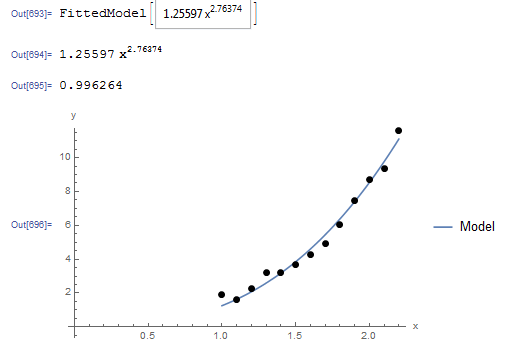
The Mathematica code is shown below.
View Mathematica CodeData = {{1, 1.93}, {1.1, 1.61}, {1.2, 2.27}, {1.3, 3.19}, {1.4, 3.19}, {1.5, 3.71}, {1.6, 4.29}, {1.7, 4.95}, {1.8, 6.07}, {1.9, 7.48}, {2, 8.72}, {2.1, 9.34}, {2.2, 11.62}};
model = NonlinearModelFit[Data, b1*x^(a1), {a1, b1}, x]
y = Normal[model]
R2 = model["RSquared"]
Plot[y, {x, 1, 2.2}, Epilog -> {PointSize[Large], Point[Data]}, PlotLegends -> {"Model"}, AxesLabel -> {"x", "y"}, AxesOrigin -> {0, 0} ]
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
Data = [[1, 1.93], [1.1, 1.61], [1.2, 2.27], [1.3, 3.19], [1.4, 3.19], [1.5, 3.71], [1.6, 4.29], [1.7, 4.95], [1.8, 6.07], [1.9, 7.48], [2, 8.72], [2.1, 9.34], [2.2, 11.62]]
def f(x, a, b): return a*x**b
coeff, covariance = curve_fit(f, [point[0] for point in Data],
[point[1] for point in Data])
print("coeff: ",coeff)
x_val = np.arange(1,2.2,0.01)
plt.title('%.5fx**(%.5f)' % tuple(coeff))
plt.plot(x_val, f(x_val, coeff[0], coeff[1]))
plt.scatter([point[0] for point in Data], [point[1] for point in Data], c='k')
plt.xlabel("x"); plt.ylabel("y")
plt.grid(); plt.show()
# R squared
x = np.array([point[0] for point in Data])
y = np.array([point[1] for point in Data])
y_fit = f(x, coeff[0], coeff[1])
ss_res = np.sum((y - y_fit)**2)
ss_tot = np.sum((y - np.mean(y))**2)
r2 = 1 - (ss_res / ss_tot)
print("R Squared: ",r2)
The following link provides the MATLAB codes for implementing the Linearization of nonlinear power model.
Muy buen articulo, fue de mucha ayuda
Thank you