
Introduction to Numerical Analysis: Linear Systems of Equations
Definitions
Linear Vector Spaces
In this course, by a linear vector space we mean the set
![\[ \mathbb{R}^n=\mathbb{R}\times\mathbb{R}\times\cdots\mathbb{R}=\left\{\left(\begin{array}{c}x_1\\x_2\\\vdots\\x_n\end{array}\right)\bigg| x_1,x_2,\cdots,x_n\in\mathbb{R} \right\} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-41215f2413089fb849da24fa4b818c33_l3.png "Rendered by QuickLaTeX.com")
The dimension of this vector space is  . A vector in this space
. A vector in this space  has components
has components  each of which is a real number. The zero vector is the vector whose components are all equal to zero.
each of which is a real number. The zero vector is the vector whose components are all equal to zero.
For example  is the two-dimensional linear vector space. Each vector in this space has two components. can be represented geometrically by a plane.
is the two-dimensional linear vector space. Each vector in this space has two components. can be represented geometrically by a plane.  is a three-dimensional linear vector space. Each vector in this space has three components. The vector
is a three-dimensional linear vector space. Each vector in this space has three components. The vector  is the zero vector in . The vector
is the zero vector in . The vector  is the zero vector in .
is the zero vector in .
Linear Functions between Vector Spaces(Matrices)
Given a linear vector space  , and another linear vector space
, and another linear vector space  , a linear function
, a linear function  has the following form,
has the following form,  :
:
![\[ f(x)=\left(\begin{array}{c} a_{11}x_1+a_{12}x_2+\cdots +a_{1m}x_m\\ a_{21}x_1+a_{22}x_2+\cdots +a_{2m}x_m\\ \vdots \\ a_{n1}x_1+a_{n2}x_2+\cdots +a_{nm}x_m \end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ba40af3313fff7b462d0652e85ab5ce3_l3.png "Rendered by QuickLaTeX.com")
The function  takes a vector
takes a vector  with
with  components and returns a vector
components and returns a vector  which has components. Using matrix notation, the above can be written in the following more convenient form:
which has components. Using matrix notation, the above can be written in the following more convenient form:
![\[ f(x)=\left(\begin{matrix}a_{11}&a_{12}&\cdots&a_{1m}\\a_{21}&a_{22}&\cdots&a_{2m}\\\vdots&\vdots&\vdots&\vdots\\a_{n1}&a_{n2}&\cdots&a_{nm}\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\\vdots\\x_m\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-75d94f3f14067090d2468eb340812bf9_l3.png "Rendered by QuickLaTeX.com")
If we denote the  matrix of numbers by
matrix of numbers by  , then the linear function can be written in the following simple form:
, then the linear function can be written in the following simple form:
![\[ f(x)=Ax \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-971f78a75bc9e83499b05a74c2cdb1b2_l3.png "Rendered by QuickLaTeX.com")
We noted that is an element of the linear vector space . Similarly, we view as an element of the possible linear functions from to which is denoted: 
If  , then for simplicity, we say that
, then for simplicity, we say that  . We also use the symbol
. We also use the symbol  to denote the set of square matrices that live in the space
to denote the set of square matrices that live in the space  .
.
For a visual representation showing the action of the matrix  on the space , see the tool shown here.
on the space , see the tool shown here.
Matrix Transpose
If  , then the transpose of , namely
, then the transpose of , namely  is defined as the matrix
is defined as the matrix  whose columns are the rows of .
whose columns are the rows of .
Examples
Example 1
Consider the function  defined as
defined as  . Following the above definition, is a one-dimensional vector and the matrix has dimensions
. Following the above definition, is a one-dimensional vector and the matrix has dimensions  . In this case
. In this case  and
and  .
.
Example 2
Consider the function  defined as follows:
defined as follows:  :
:
![\[ f(x)=\left(\begin{array}{c}5x_1+3x_2+2x_3\\2x_2+4x_3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-d32a0708a093d268758aa5b3d9a3b808_l3.png "Rendered by QuickLaTeX.com")
In matrix form, this function can be represented as follows:
![\[ f(x)=\left(\begin{array}{ccc}5&3&2\\0&2&4\end{array}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-7a7c60fcca8faf2a14181322554e70d1_l3.png "Rendered by QuickLaTeX.com")
This function takes vectors that have three components and gives vectors that have two components. The matrix associated with this linear function has dimensions  , lives in the space
, lives in the space  , and has the form:
, and has the form:
![\[ A=\left(\begin{array}{ccc}5&3&2\\0&2&4\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-01e73d29b1f2c99c60a97512a057d68f_l3.png "Rendered by QuickLaTeX.com")
In this case, is simply:
![\[ A^T=\left(\begin{array}{cc}5&0\\3&2\\2&4\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-4fbd748d1805a648d6a7fe6d75a15e4c_l3.png "Rendered by QuickLaTeX.com")
Example 3
Consider the function  defined as follows: :
defined as follows: :
![\[ f(x)=\left(\begin{array}{c}5x_1+3x_2+2x_3\\2x_2+4x_3\\2x_1-3x_3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-f7033cba98b31392418999f7b76b3a52_l3.png "Rendered by QuickLaTeX.com")
In matrix form, this function can be represented as follows:
![\[ f(x)=\left(\begin{array}{ccc}5&3&2\\0&2&4\\2&0&-3\end{array}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-2271b9bf899f90717ecbd22f8eb2504b_l3.png "Rendered by QuickLaTeX.com")
This function takes vectors that have three components and gives vectors that have three components. The matrix associated with this linear function has dimensions  , lives in the space
, lives in the space  , and has the form:
, and has the form:
![\[ A=\left(\begin{array}{ccc}5&3&2\\0&2&4\\2&0&-3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-e826d3bbf2de048b79a214b821202bb7_l3.png "Rendered by QuickLaTeX.com")
In this case, is simply:
![\[ A^T=\left(\begin{array}{ccc}5&0&2\\3&2&0\\2&4&-3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-d6b5b3e5b9b968a03392545ff230a722_l3.png "Rendered by QuickLaTeX.com")
Example 4
Consider the function  defined as follows: :
defined as follows: :
![\[ f(x)=\left(\begin{array}{c}5x_1+2x_3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-c21ecdccfef5328b9aa3515610b4ff40_l3.png "Rendered by QuickLaTeX.com")
In matrix form, this function can be represented as follows:
![\[ f(x)=\left(\begin{array}{ccc}5&0&2\end{array}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-f34beff8b9b7796aeafc9ce579a9a735_l3.png "Rendered by QuickLaTeX.com")
This function takes vectors that have three components and gives vectors that have one component. The matrix associated with this linear function has dimensions  , lives in the space
, lives in the space  , and has the form:
, and has the form:
![\[ A=\left(\begin{array}{ccc}5&0&2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-1eefbe70f049f54e429ecf9654f9b7d4_l3.png "Rendered by QuickLaTeX.com")
In this case, is simply:
![\[ A^T=\left(\begin{array}{c}5\\0\\2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-cd85db17de5b90d65049d99aa81973c4_l3.png "Rendered by QuickLaTeX.com")
Linear System of Equations
Let and given a vector  , a linear system of equations seeks the solution to the equation:
, a linear system of equations seeks the solution to the equation:
![\[ Ax=b \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-bac17a30269bdf75b8358db1dc1102f9_l3.png "Rendered by QuickLaTeX.com")
In a matrix component form the above equation is:
![\[ \left(\begin{matrix}a_{11}&a_{12}&\cdots&a_{1m}\\a_{21}&a_{22}&\cdots&a_{2m}\\\vdots&\vdots&\vdots&\vdots\\a_{n1}&a_{n2}&\cdots&a_{nm}\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\\vdots\\x_m\end{array}\right)=\left(\begin{array}{c}b_1\\b_2\\\vdots\\b_n\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-996d7a8461f241a2cd64059b884e8b39_l3.png "Rendered by QuickLaTeX.com")
Another way of viewing this set of equations is as follows:
![\[\begin{split} a_{11}x_1+a_{12}x_2+\cdots +a_{1m}x_m&=b_1\\ a_{21}x_1+a_{22}x_2+\cdots +a_{2m}x_m&=b_2\\ &\vdots \\ a_{n1}x_1+a_{n2}x_2+\cdots +a_{nm}x_m&=b_n \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-f0478bbb8ab7de073b43f700e69555d6_l3.png "Rendered by QuickLaTeX.com")
The solution for a linear system of equations is the numerical value for the variables  that would satisfy the above equations. There are three possible scenarios:
that would satisfy the above equations. There are three possible scenarios:
Scenario 1
If  then we have more unknown components of the -dimensional vector than we have equations. The system is then termed underdetermined. This results in having many possible solutions. For example, consider the linear system of equations
then we have more unknown components of the -dimensional vector than we have equations. The system is then termed underdetermined. This results in having many possible solutions. For example, consider the linear system of equations  defined as:
defined as:
![\[ \left(\begin{array}{ccc}5&3&2\\0&2&4\end{array}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{array}{c}1\\2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-02848490b93104db9e3f07a700add2ad_l3.png "Rendered by QuickLaTeX.com")
There are many possible solutions that would satisfy the above equation. One solution can be obtained by setting  . Then:
. Then:
![\[\begin{split} 5x_1+3x_2+2&=1\\ 2x_2+4&=2 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-d949165cf88d7f8112a21798914f5b4d_l3.png "Rendered by QuickLaTeX.com")
which results in  and
and  . Therefore one possible solution is:
. Therefore one possible solution is:
![\[ x=\left(\begin{array}{c}\frac{2}{5}\\-1\\1\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-e6d8ae83e908d48df24c6d1cdd837494_l3.png "Rendered by QuickLaTeX.com")
Another possible solution can be obtained by setting  . Then:
. Then:
![\[\begin{split} 5x_1+3x_2+4&=1\\ 2x_2+8&=2 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-7383b04c18c4521bf87b185adcfd115b_l3.png "Rendered by QuickLaTeX.com")
which results in  and
and  . Therefore another possible solution is:
. Therefore another possible solution is:
![\[ x=\left(\begin{array}{c}\frac{6}{5}\\-3\\2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-de6c4648ba21520e83471a1373d5a133_l3.png "Rendered by QuickLaTeX.com")
In fact, there are infinite possible solutions that depend on what value you choose for  . So, if is set such that
. So, if is set such that  , then we have:
, then we have:
![\[\begin{split} 5x_1+3x_2+2\alpha&=1\\ 2x_2+4\alpha&=2 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-6d009ddb211c8800ca4db4b71e6bf74d_l3.png "Rendered by QuickLaTeX.com")
Therefore:
![\[ x_2=\frac{2-4\alpha}{2}=1-2\alpha \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ee546e965c6a7a0a7abf2922739cf436_l3.png "Rendered by QuickLaTeX.com")
and
![\[ x_1=\frac{1}{5}(1-2\alpha - 3(1-2\alpha))=\frac{1}{5}(-2+4\alpha) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-7d140720909ba8581e42891fb260230e_l3.png "Rendered by QuickLaTeX.com")
Therefore:
![\[ x=\left(\begin{array}{c}\frac{-2+4\alpha}{5}\\1-2\alpha\\\alpha\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-5283dbe5a2e2df17bfb9a1132669428e_l3.png "Rendered by QuickLaTeX.com")
Scenario 2
If  and the equations are linearly independent, then we have more equations than we have unknown components of the -dimensional vector . This results in having too many restrictions which prevents us from finding a solution. In this case, the system is termed overdetermined. For example, consider the linear system of equations defined as:
and the equations are linearly independent, then we have more equations than we have unknown components of the -dimensional vector . This results in having too many restrictions which prevents us from finding a solution. In this case, the system is termed overdetermined. For example, consider the linear system of equations defined as:
![\[ \left(\begin{array}{cc}1&3\\0&2\\-1&1\end{array}\right)\left(\begin{array}{c}x_1\\x_2\end{array}\right)=\left(\begin{array}{c}1\\2\\2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ef451fd19e267354b2a30d5210556124_l3.png "Rendered by QuickLaTeX.com")
In this system, we have three independent equations and two unknowns  and
and  . If the first two equations are used to find a solution, then the third equation will present a contradiction. The first two equations have the following form:
. If the first two equations are used to find a solution, then the third equation will present a contradiction. The first two equations have the following form:
![\[\begin{split} x_1+3x_2&=1\\ 2x_2&=2 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-7bb206c478090ae5f43508798af9447f_l3.png "Rendered by QuickLaTeX.com")
which result in the solution  , and
, and  . If we substitute this solution into equation 3 we get:
. If we substitute this solution into equation 3 we get:
![\[ -1\times (-2)+1\times 1=2+1=3\neq 2 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-34a129304296459eb97c40e3971fa524_l3.png "Rendered by QuickLaTeX.com")
Scenario 3
If  and the equations are independent, i.e., the rows of the matrix are linearly independent, then one unique solution exists and the matrix that forms the equation has an inverse. In this case, there exists a matrix
and the equations are independent, i.e., the rows of the matrix are linearly independent, then one unique solution exists and the matrix that forms the equation has an inverse. In this case, there exists a matrix  such that:
such that:
![\[ Ax=b\Rightarrow x=A^{-1}b \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-392111ffa599ee3dec8ad19237754df7_l3.png "Rendered by QuickLaTeX.com")
To know whether the equations are independent or not the determinant function defined below is sufficient. If the determinant of a matrix is equal to 0, then the rows of the matrix are linearly dependent, and so, an inverse cannot be found. If the determinant of a matrix on the other hand is not equal to 0, then the rows of the matrix are linearly independent and an inverse can be found.
For example, consider the system defined as:
![\[ \left(\begin{array}{cc}1&3\\0&2\end{array}\right)\left(\begin{array}{c}x_1\\x_2\end{array}\right)=\left(\begin{array}{c}1\\2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-8dceadfb581e8d307ae88f10585aab8a_l3.png "Rendered by QuickLaTeX.com")
The rows of the matrix are clearly linearly independent. The inverse of can be found (which will be discussed later in more detail). For now, we can simply solve the two equations as follows. From the second equation we get:
![\[ 2x_2=2\Rightarrow x_2=1 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-5a15ae962b84ee6f8035c4a03d797642_l3.png "Rendered by QuickLaTeX.com")
Substituting into the first equation we get:
![\[ x_1+3(1)=1\Rightarrow x_1=-2 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-a78b915365226492b7f9065dc6825db6_l3.png "Rendered by QuickLaTeX.com")
Therefore, the system has a unique solution.
If and the equations are dependent, i.e., the rows of the matrix are linearly dependent, then it is not possible to find a unique solution for the linear system of equations. For example, consider the system defined as:
![\[ \left(\begin{array}{cc}1&1\\-1&-1\end{array}\right)\left(\begin{array}{c}x_1\\x_2\end{array}\right)=\left(\begin{array}{c}1\\2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-fc97b142f3f58220bf7bd1fdce1373c5_l3.png "Rendered by QuickLaTeX.com")
The rows of the matrix are clearly linearly dependent. The inverse of can not be found (which will be discussed later in more detail). The system presents a contradiction and cannot be solved because the first equation predicts that  while the second equation predicts that
while the second equation predicts that  !
!
As a different example, consider the system defined as:
![\[ \left(\begin{array}{cc}1&1\\-1&-1\end{array}\right)\left(\begin{array}{c}x_1\\x_2\end{array}\right)=\left(\begin{array}{c}1\\-1\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-24f411940b358214e5d1de74dd9ebb26_l3.png "Rendered by QuickLaTeX.com")
The rows of the matrix are clearly linearly dependent. The inverse of can not be found (which will be discussed later in more detail). The system has infinite number of possible solutions. The first and second equations give us the relationship  . So, by assuming any value for , we can find a value for . For example, if
. So, by assuming any value for , we can find a value for . For example, if  , then
, then  . Another possible solution is
. Another possible solution is  and .
and .
We will focus in the remaining part of this section on how to find a solution for a linear system of equations when .
Special Types of Square Matrices
Symmetric Matrix
A symmetric matrix is a matrix that satisfies . For example:
![\[ A=\left(\begin{array}{cc}1&3\\3&2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-bfada02894a6a18cc27c848816485fd2_l3.png "Rendered by QuickLaTeX.com")
is a symmetric matrix.
Identity Matrix
The identity matrix  is the matrix whose diagonal components have the value of 1 while its off diagonal components have a value of zero. For example,
is the matrix whose diagonal components have the value of 1 while its off diagonal components have a value of zero. For example,  has the form:
has the form:
![\[ I=\left(\begin{array}{ccc}1&0&0\\0&1&0\\0&0&1\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-e4bf02689c68eec80797a7aa349ba72c_l3.png "Rendered by QuickLaTeX.com")
This is called the identity matrix because it takes every vector and returns the same vector. For example, consider the general vector  with components , , and . The same vector is obtained after the operation
with components , , and . The same vector is obtained after the operation  :
:
![\[ Ix=\left(\begin{array}{ccc}1&0&0\\0&1&0\\0&0&1\end{array}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=x \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-adc1aea4f436c37e0e6591076776e750_l3.png "Rendered by QuickLaTeX.com")
Diagonal Matrix
A matrix  is called diagonal if all its off diagonal components are zero. The identity matrix is a diagonal matrix. Similarly, the following matrix is diagonal:
is called diagonal if all its off diagonal components are zero. The identity matrix is a diagonal matrix. Similarly, the following matrix is diagonal:
![\[ M=\left(\begin{array}{cccc}5&0&0&0\\0&-1&0&0\\0&0&0&0\\0&0&0&-3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ae78cb2f5bfb508b610e49836c52c97d_l3.png "Rendered by QuickLaTeX.com")
Upper Triangular Matrix
Let .  is an upper triangular matrix if all the components below the diagonal components are equal to zero. For example, the following matrix is an upper triangular matrix:
is an upper triangular matrix if all the components below the diagonal components are equal to zero. For example, the following matrix is an upper triangular matrix:
![\[ M=\left(\begin{matrix}1&2&3\\0&1&4\\0&0&5\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-459558072df006119fcbcb283bad63a0_l3.png "Rendered by QuickLaTeX.com")
Lower Triangular Matrix
Let . is a lower triangular matrix if all the components above the diagonal components are equal to zero. For example, the following matrix is a lower triangular matrix:
![\[ M=\left(\begin{matrix}1&0&0&0\\5&2&0&0\\2&3&1&0\\1&2&0&3\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-5af11b0024f182098c46ff0d850d5007_l3.png "Rendered by QuickLaTeX.com")
Banded Matrix
A matrix is called banded if all its components are zero except the components on the main diagonal and one or more diagonals on either side. The band width is the maximum number of columns on the same row that have non-zero entries. For example, the following  is banded with a band width of 3.
is banded with a band width of 3.
![\[ M=\left(\begin{matrix}1&0&0&0&0\\1&2&3&0&0\\0&3&1&2&0\\0&0&1&2&3\\0&0&0&4&4\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-bd56ed3872f8ceb05819f3efa4db1eb9_l3.png "Rendered by QuickLaTeX.com")
Matrix Operations
Matrix Addition
Let  . Consider the function
. Consider the function  and the function
and the function  . Then, the function
. Then, the function  is given as:
is given as:
![\[ f_3(x)=M_1x+M_2x=(M_1+M_2)x=M_3x \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-9c18dc34bcc42ab45e0a8b73e62f0c80_l3.png "Rendered by QuickLaTeX.com")
where  is computed by adding each component in
is computed by adding each component in  to the corresponding component in
to the corresponding component in  . For example, consider the two matrices:
. For example, consider the two matrices:
![\[ M_1=\left(\begin{matrix}5&2\\0&1\end{matrix}\right) \qquad M_2=\left(\begin{matrix}-1&0\\2&2\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-96384a4ada5684893bc747800b8be907_l3.png "Rendered by QuickLaTeX.com")
Then, the matrix  can be computed as follows:
can be computed as follows:
![\[ M_3=M_1+M_2=\left(\begin{matrix}4&2\\2&3\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-0336134c2ae637b6090ad9d4a08e50b4_l3.png "Rendered by QuickLaTeX.com")
Two matrices can only be added if they have the same dimensions.
Matrix Multiplication
Consider the matrix  which takes vectors of dimensions and returns vectors of dimensions . The matrix has dimensions . Consider the matrix
which takes vectors of dimensions and returns vectors of dimensions . The matrix has dimensions . Consider the matrix  which takes vectors of dimension and gives vectors of dimension
which takes vectors of dimension and gives vectors of dimension  . The matrix
. The matrix  has dimensions
has dimensions  . The combined operation
. The combined operation  takes vectors of dimensions and gives vectors of dimension . This matrix
takes vectors of dimensions and gives vectors of dimension . This matrix  corresponding to the combined operation can be obtained by taking the dot product of the row vectors of the matrix with the column vectors of the matrix . This can only be done if the inner dimensions are equal to each other. The product would have dimensions of
corresponding to the combined operation can be obtained by taking the dot product of the row vectors of the matrix with the column vectors of the matrix . This can only be done if the inner dimensions are equal to each other. The product would have dimensions of  and it is such that
and it is such that  :
:
![\[ L_{l\times m}=N_{l\times n}M_{n\times m} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-162e5a483bf85537a28d4148e3bc8c21_l3.png "Rendered by QuickLaTeX.com")
For example, consider the two matrices:
![\[ N=\left(\begin{array}{cc}1&4\\2&2\\3&5\end{array}\right) \qquad M=\left(\begin{array}{cccc}2&3&1&5\\0&-1&2&4\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-b7c5b68ba2677c6f17cb0b2926a6c7c6_l3.png "Rendered by QuickLaTeX.com")
We can only perform the operation but the opposite is not defined. The matrix multiplication results in:
![\[ L=\left(\begin{array}{cccc} 1\times 2+ 4\times 0 & 1\times 3-4\times 1 & 1\times 1+4\times 2 & 1\times 5 + 4\times 4\\ 2\times 2+ 2\times 0 & 2\times 3-2\times 1 & 2\times 1+2\times 2 & 2\times 5 + 2\times 4\\ 3\times 2+ 5\times 0 & 3\times 3-5\times 1 & 3\times 1+5\times 2 & 3\times 5 + 5\times 4 \end{array}\right)=\left(\begin{array}{cccc}2&-1&9&21\\4&4&6&18\\6&4&13&35\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-d110cf659e42e1260cb9653cc9a73769_l3.png "Rendered by QuickLaTeX.com")
You can use “.” in Mathematica to multiply matrices, or you can use “MMULT” in excel to multiply matrices.
View Mathematica Code
Nn = {{1, 4}, {2, 2}, {3, 5}};
M = {{2, 3, 1, 5}, {0, -1, 2, 4}};
L = Nn.M;
L // MatrixForm
It is important to note that when the dimensions are appropriate, then matrix multiplication is associative and distributive, i.e., given the three matrices  then:
then:
![\[ A(BC)=(AB)C \qquad A(B+C)=AB+AC \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-18c288cb14bfeb84c9a609ded39d8648_l3.png "Rendered by QuickLaTeX.com")
However, matrix multiplication is not necessarily commutative, i.e.,  . For example, consider the matrices
. For example, consider the matrices
![\[ A=\left(\begin{array}{cc}1&2\\0&0\end{array}\right) \qquad B=\left(\begin{array}{cc}1&1\\-1&1\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-5dfd98cf846f0585737512f6dfc0716f_l3.png "Rendered by QuickLaTeX.com")
Then:
![\[ AB=\left(\begin{array}{cc}-1&3\\0&0\end{array}\right) \neq BA=\left(\begin{array}{cc}1&2\\-1&-2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-7ef6c01578279cabf73113bceb72f24b_l3.png "Rendered by QuickLaTeX.com")
Matrix Determinant
If  such that:
such that:
![\[ M=\left(\begin{matrix}a_1 &a_2\\b_1 & b_2\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-3bca71206708502c4ce085e1bf293d15_l3.png "Rendered by QuickLaTeX.com")
then  . If
. If  such that:
such that:
![\[ M=\left(\begin{matrix}a_1 &a_2&a_3\\b_1 & b_2&b_3\\c_1&c_2&c_3\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-df8b63f15d08eb31ef618b1ca650b5e1_l3.png "Rendered by QuickLaTeX.com")
then  .
.
Let . The matrix determinant can be defined using the recursive relationship:
![\[ \det{M}=\sum_{i=1}^n(-1)^{(i+1)}M_{1i}\det{N_i} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-a459296a358ec0620b971bfb19bf0ce5_l3.png "Rendered by QuickLaTeX.com")
where  and is formed by eliminating the 1st row and
and is formed by eliminating the 1st row and  column of the matrix . It can be shown that
column of the matrix . It can be shown that  the rows of are linearly dependent. In other words,
the rows of are linearly dependent. In other words,  if and only if the matrix cannot be inverted. The function “Det[]” in Mathematica can be used to calculate the determinant of a matrix. In Excel, you can use the function “MDETERM()” to calculate the determinant of a matrix as well.
if and only if the matrix cannot be inverted. The function “Det[]” in Mathematica can be used to calculate the determinant of a matrix. In Excel, you can use the function “MDETERM()” to calculate the determinant of a matrix as well.
The following function in Mathematica computes the determinant of the matrix using the above recursive relationship and then compares the solution with the built-in function “Det[]” in Mathematica.
View Mathematica Code
fdet[M_] := (n = Length[M]; If[n == 2, (M[[1, 1]]*M[[2, 2]] - M[[1, 2]]*M[[2, 1]]),Sum[(-1)^(i + 1) M[[1, i]]*fdet[Drop[M, 1, {i}]], {i, 1, n}]]);
M = {{1, 1, 3, 7}, {4, 4, 5, 0}, {1, 5, 5, 6}, {1, -4, 3, -2}};
fdet[M]
Det[M]
You can check the section on the determinant of a matrix for additional information on some of the properties of the determinant of a matrix.
Solving Systems of Linear Equations
Solving systems of linear equations has been the subject of study for many centuries. In particular, for every engineering discipline and almost every engineering application, systems of linear equations appear naturally with large numbers of unknowns. For example, the stiffness method in structural analysis as well as the finite element analysis method seek to find the solution of the linear system of equations  where
where  is a symmetric matrix of dimensions
is a symmetric matrix of dimensions  ,
,  is a vector of external forces and
is a vector of external forces and  is the vector of the displacement of the structure nodes. The software used need to implement a method by which can be obtained given particular values for . An appropriate method to solve for a linear system of equations has to be computationally efficient. In the following, we will present a few methods to solve systems in which the number of equations is equal to the number of unknowns along with their pros and cons.
is the vector of the displacement of the structure nodes. The software used need to implement a method by which can be obtained given particular values for . An appropriate method to solve for a linear system of equations has to be computationally efficient. In the following, we will present a few methods to solve systems in which the number of equations is equal to the number of unknowns along with their pros and cons.
Cramer’s Rule
Cramer’s rule is one of the early methods to solve systems of linear equations . It is dated back to the eighteenth century! The method works really well; however, it is inefficient when the number of equations is very large. Nevertheless, with the current computing capabilities, the method can still be pretty fast. The method works using the following steps. First, the determinant of the matrix is calculated. Each component  of the unknowns can be computed as:
of the unknowns can be computed as:
![\[ x_i=\frac{\det{D_i}}{\det{A}} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-62cdc5cdef1e7c795d534579b854bba5_l3.png "Rendered by QuickLaTeX.com")
where  is the matrix formed by replacing the column in with the vector
is the matrix formed by replacing the column in with the vector  .
.
Example 1
Consider the linear system of equations defined as:
![\[ \left(\begin{matrix}1&2\\-2&1\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\end{array}\right)=\left(\begin{array}{c}-1\\2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ee9c05d56e58a77f736cf52f28c50a5d_l3.png "Rendered by QuickLaTeX.com")
 . We will form the following two matrices by replacing the first column in with and then the second column in with :
. We will form the following two matrices by replacing the first column in with and then the second column in with :
![\[ D_1=\left(\begin{matrix}-1&2\\2&1\end{matrix}\right) \qquad D_2=\left(\begin{matrix}1&-1\\-2&2\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-c20d946ba94aeaab0e8d8408076516bc_l3.png "Rendered by QuickLaTeX.com")
The determinants of these matrices are:
![\[ \det{D_1}=-1\times 1-2\times 2=-5 \qquad \det{D_2}=1\times 2-2\times 1=0 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-d1c68e913821b1789e32bcc9b78f853e_l3.png "Rendered by QuickLaTeX.com")
Therefore:
![\[ x_1=\frac{\det{D_1}}{\det{A}}=\frac{-5}{5}=-1 \qquad x_2=\frac{\det{D_2}}{\det{A}}=\frac{0}{5}=0 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-e491bb11e11b7d49706ab4e83a81d463_l3.png "Rendered by QuickLaTeX.com")
The following is code that can be used for Cramer’s rule for a two-dimensional system of equations.
View Mathematica CodeA = {{a11, a12}, {a21, a22}};
AT = Transpose[A]
b = {b1, b2};
s1 = Drop[AT, {1}]
s2 = Drop[AT, {2}]
D1T = Insert[s1, b, 1]
D2T = Insert[s2, b, 2]
D1 = Transpose[D1T]
D2 = Transpose[D2T]
x1 = Det[D1]/Det[A]
x2 = Det[D2]/Det[A]
Example 2
Consider the linear system of equations defined as:
![\[ \left(\begin{matrix}1&2&3\\2&1&4\\1&3&5\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{array}{c}-4\\8\\0\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-2da2d996d6075317fd058b6d34234b31_l3.png "Rendered by QuickLaTeX.com")
 . We will form the following three matrices by replacing the corresponding columns in with :
. We will form the following three matrices by replacing the corresponding columns in with :
![\[ D_1=\left(\begin{matrix}-4&2&3\\8&1&4\\0&3&5\end{matrix}\right) \qquad D_2=\left(\begin{matrix}1&-4&3\\2&8&4\\1&0&5\end{matrix}\right) \qquad D_3=\left(\begin{matrix}1&2&-4\\2&1&8\\1&3&0\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-a8ae1f82faa0652693fb715b578375bf_l3.png "Rendered by QuickLaTeX.com")
The determinants of these matrices are:
![\[ \det{D_1}=20 \qquad \det{D_2}=40 \qquad \det{D_3}=-28 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-e27bc7a129b486f5cafade13d73a44bb_l3.png "Rendered by QuickLaTeX.com")
Therefore:
![\[ x_1=\frac{\det{D_1}}{\det{A}}=-5 \qquad x_2=\frac{\det{D_2}}{\det{A}}=-10 \qquad x_3=\frac{\det{D_3}}{\det{A}}=7 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-72eedada335260f089f703410c29a375_l3.png "Rendered by QuickLaTeX.com")
The following procedure applies the Cramer’s rule to a general system. Test the procedure to see how fast it is for higher dimensions.
View Mathematica Code
Cramer[A_, b_] := (n = Length[A];
Di = Table[A, {i, 1, n}];
Do[Di[[i]][[All, i]] = b, {i, 1, n}];
x = Table[Det[Di[[i]]]/Det[A], {i, 1, n}])
A = {{1, 2, 3, 5}, {2, 0, 1, 4}, {1, 2, 2, 5}, {4, 3, 2, 2}};
b = {-4, 8, 0, 10};
Cramer[A, b]
The following link provides the MATLAB code for implementing the Cramer’s rule.
Naive Gauss Elimination
The naive Gauss elimination is a procedure in which the linear system of equations is manipulated such that the coefficients of the component are eliminated from equation  to equation . It would then be possible to solve for
to equation . It would then be possible to solve for  using the last equation, and then backward substitute to find the remaining components. The procedure is divided into two steps, forward elimination followed by backward substitution. We will illustrate the process in the following example. Consider the system of equations defined as:
using the last equation, and then backward substitute to find the remaining components. The procedure is divided into two steps, forward elimination followed by backward substitution. We will illustrate the process in the following example. Consider the system of equations defined as:
![\[\begin{split} 2x_1+2x_2+2x_3&=6\\ 2x_1+3x_2+4x_3&=4\\ -x_1+2x_2+3x_3&=8\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-e0c6bc7acc24184d6721a7da375fc308_l3.png "Rendered by QuickLaTeX.com")
Forward elimination: First, we will use the first equation to eliminate the coefficients of in equation 2 and 3. By multiplying the first equation by -1 and adding it to the second equation we get:
![\[\begin{split} 2x_1+2x_2+2x_3&=6\\ (2-2)x_1+(3-2)x_2+(4-2)x_3&=(4-6)\\ -x_1+2x_2+3x_3&=8\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-6f624f6ec9842d4ff5552d0881d1b957_l3.png "Rendered by QuickLaTeX.com")
which becomes:
![\[\begin{split} 2x_1+2x_2+2x_3&=6\\ 0+1x_2+2x_3&=-2\\ -x_1+2x_2+3x_3&=8\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-a9fcd5b41c83d0a5dc78b6e378e0daf5_l3.png "Rendered by QuickLaTeX.com")
By multiplying the first equation by  and adding it to the third equation we get:
and adding it to the third equation we get:
![\[\begin{split} 2x_1+2x_2+2x_3&=6\\ 0+1x_2+2x_3&=-2\\ 0+3x_2+4x_3&=11\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ce00ad9e7f1f89e30fedc23d485ad790_l3.png "Rendered by QuickLaTeX.com")
We are now ready to eliminate the coefficient of from equation 3 by multiplying equation 2 by -3 and adding it to equation 3:
![\[\begin{split} 2x_1+2x_2+2x_3&=6\\ 0+1x_2+2x_3&=-2\\ 0+0-2x_3&=17\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-a43e5cf864220463131200c08ad1e29d_l3.png "Rendered by QuickLaTeX.com")
Backward substitution: Solving the above system becomes very simple. is straightforward, it is equal to  . can be obtained from the second equation as:
. can be obtained from the second equation as:  and finally
and finally  . Therefore, the solution is:
. Therefore, the solution is:
![\[ x=\left(\begin{array}{c}-3.5\\15\\-8.5\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-29b2a8fb6a85bebbcd86984256f2db00_l3.png "Rendered by QuickLaTeX.com")
Of course, as expected, if we multiply the original by we should get the matrix .
The Naive Gauss elimination method can be implemented in matrix form of dimensions  as follows:
as follows:
![\[ \left(\begin{array}{ccc|c}2&2&2&6\\2&3&4&4\\-1&2&3&8\end{array}\right)\Rightarrow \left(\begin{array}{ccc|c}2&2&2&6\\0&1&2&-2\\-1&2&3&8\end{array}\right) \Rightarrow \left(\begin{array}{ccc|c}2&2&2&6\\0&1&2&-2\\0&3&4&11\end{array}\right) \Rightarrow \left(\begin{array}{ccc|c}2&2&2&6\\0&1&2&-2\\0&0&-2&17\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-0748352b12f949c2f09015d9a2bf095f_l3.png "Rendered by QuickLaTeX.com")
The following code implements the above calculations in Mathematica
View Mathematica Code
A = {{2, 2, 2}, {2, 3, 4}, {-1, 2, 3}};
b = {6, 4, 8};
Aa = {{2, 2, 2, b[[1]]}, {2, 3, 4, b[[2]]}, {-1, 2, 3, b[[3]]}};
Aa[[2]] = Aa[[2]] + -1*Aa[[1]]
Aa[[3]] = Aa[[3]] + 1/2*Aa[[1]]
Aa[[3]] = Aa[[3]] - 3 Aa[[2]]
Aa // MatrixForm
x3 = Aa[[3, 4]]/Aa[[3, 3]]
x2 = (Aa[[2, 4]] - Aa[[2, 3]]*x3)/Aa[[2, 2]]
x1 = (Aa[[1, 4]] - Aa[[1, 2]]*x2 - Aa[[1, 3]]*x3)/Aa[[1, 1]]
Programming the Method
The following are the steps to program the Naive Gauss Elimination method. Assuming an number of equations in unknowns of the form :
- Form the combined matrix

- Forward elimination: Use the pivot elements
 on the row
on the row  as “Pivot” elements. Use the “Pivot” elements to eliminate the components
as “Pivot” elements. Use the “Pivot” elements to eliminate the components  with
with  from
from  to . This is done by iterating from to and for each row , doing the operation
to . This is done by iterating from to and for each row , doing the operation  .
. - Backward substitution: The element with running backwards from to 1 can be found using the equation:
![\[ x_i=\frac{G_{i(n+1)}-\sum_{l=i+1}^nG_{il}x_l}{G_{ii}} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-42ff4dd903d9b2b1310d57b34def779b_l3.png "Rendered by QuickLaTeX.com")
The following is the code that relies on the “Sum” built-in function in Mathematica.
View Mathematica Code
(*Procedure*)
GaussElimination[A_, b_] :=
(n = Length[A];
G = Transpose[Insert[Transpose[A], b, n + 1]];
For[k = 1, k <= n, k++,
Do[G[[i]] = G[[i]] - G[[i, k]]/G[[k, k]]*G[[k]], {i, k + 1, n}]];
x = Table[0, {i, 1, n}];
For[i = n, i >= 1, i = i - 1,
x[[i]] = (G[[i, n + 1]] - Sum[G[[i, l]]*x[[l]], {l, i + 1, n}])/G[[i, i]]];
x)
(*An example*)
A = {{1, 2, 3, 5}, {2, 0, 1, 4}, {1, 2, 2, 5}, {4, 3, 2, 2}};
b = {-4, 8, 0, 10};
(*Applying the procedure to the example*)
N[GaussElimination[A, b]]
GaussElimination[A, b]
The following is the code that does not rely on the built-in function in Mathematica.
View Mathematica Code(*Procedure*)
GaussElimination[A_, b_] := (n = Length[A];
G = Transpose[Insert[Transpose[A], b, n + 1]];
For[k = 1, k <= n, k++,
Do[G[[i]] = G[[i]] - G[[i, k]]/G[[k, k]]*G[[k]], {i, k + 1, n}]];
x = Table[0, {i, 1, n}];
For[i = n, i >= 1,
i = i - 1, (BB = 0; Do[BB = G[[i, l]]*x[[l]] + BB, {l, i + 1, n}];
x[[i]] = (G[[i, n + 1]] - BB)/G[[i, i]])];
x)
(*An example*)
A = {{1, 2, 3, 5}, {2, 0, 1, 4}, {1, 2, 2, 5}, {4, 3, 2, 2}};
b = {-4, 8, 0, 10};
(*Applying the procedure to the example*)
N[GaussElimination[A, b]]
GaussElimination[A, b]
Naive?
The method described above is considered “naive” for two reasons. The first reason is that it fails to find a solution if a pivot element (one of the diagonal elements) is found to be zero. For example, consider the linear system:
![\[ \left(\begin{matrix}1&0&0\\0&0&1\\0&1&0\end{matrix}\right)\left(\begin{matrix}x_1\\x_2\\x_3\end{matrix}\right)=\left(\begin{matrix}1\\1\\1\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-0d383565189f024d2edc9dbf8973da09_l3.png "Rendered by QuickLaTeX.com")
This is really simple and the solution is just  . However, the code fails to find a solution because when the second row is used for elimination, the pivot element
. However, the code fails to find a solution because when the second row is used for elimination, the pivot element  is equal to zero, and so, an error is encountered. Try the above systems out and see the error that Mathematica spits out. This problem can be solved by simply exchanging rows 2 and 3. The same issue will be encountered for the following system:
is equal to zero, and so, an error is encountered. Try the above systems out and see the error that Mathematica spits out. This problem can be solved by simply exchanging rows 2 and 3. The same issue will be encountered for the following system:
![\[ \left(\begin{matrix}1&1&0\\0&0&1\\1&0&0\end{matrix}\right)\left(\begin{matrix}x_1\\x_2\\x_3\end{matrix}\right)=\left(\begin{matrix}1\\1\\1\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-9f4007af5dbd4699a7c909676be98b65_l3.png "Rendered by QuickLaTeX.com")
In this case, one solution would be to rearrange the equations such that equation 3 would be equation 1. In general, the naive Gauss elimination code presented above can be augmented so that the pivot elements are chosen to be the largest elements in the column below. This augmentation is termed: “Partial Pivoting”. Partial Pivoting is performed by exchanging the rows. In this case, the order of the variables stays the same. In rare cases, there could be a need to exchange the columns as well; a procedure termed “Complete Pivoting”, but this adds the complication of re-arranging the variables.
The second reason why it is called naive is that the method essentially produces an upper triangular matrix that can be easily solved. It is important to note that if the system is already a lower triangular matrix, then there is no need to employ the forward elimination procedure, because we can simply use forward substitution to find  in this order.
in this order.
Consider the following system:
![\[ \left(\begin{matrix}1&0&0\\1&1&0\\1&1&1\end{matrix}\right)\left(\begin{matrix}x_1\\x_2\\x_3\end{matrix}\right)=\left(\begin{matrix}1\\0\\1\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-75ec75ca5ace172c73a2e39d9d872012_l3.png "Rendered by QuickLaTeX.com")
It is straightforward that ,  , and
, and  . However, employing the naive Gauss elimination would conduct the following steps:
. However, employing the naive Gauss elimination would conduct the following steps:
![\[ \left(\begin{array}{ccc|c}1&0&0&1\\1&1&0&0\\1&1&1&1\end{array}\right)\Rightarrow \left(\begin{array}{ccc|c}1&0&0&1\\0&1&0&-1\\1&1&1&1\end{array}\right) \Rightarrow \left(\begin{array}{ccc|c}1&0&0&1\\0&1&0&-1\\0&1&1&0\end{array}\right) \Rightarrow \left(\begin{array}{ccc|c}1&0&0&1\\0&1&0&-1\\0&0&1&1\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-b23d3d487ef40a97a11f74006fa55c85_l3.png "Rendered by QuickLaTeX.com")
Gauss-Jordan Elimination
Another method that is rooted in the Gauss elimination method is the Gauss-Jordan elimination method. Two steps are added to the previous algorithm. The first step is that each pivot row is normalized by the pivot element. The second step is that the coefficients above the pivot element are also eliminated. This results in not needing the backward substitution step. The following example illustrates the method. Consider the system of equations defined as:
The first row is normalized:
![\[\begin{split} x_1+x_2+x_3&=3\\ 2x_1+3x_2+4x_3&=4\\ -x_1+2x_2+3x_3&=8\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-6d885d67d21d01805daa090c512fed09_l3.png "Rendered by QuickLaTeX.com")
The first (pivot) row is used to eliminate the coefficients of in the second and third rows:
![\[\begin{split} x_1+x_2+x_3&=3\\ 0+1x_2+2x_3&=-2\\ 0+3x_2+4x_3&=11\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-cfa88d398ff0f2bc2477ad22715fc304_l3.png "Rendered by QuickLaTeX.com")
The second row is already normalized and can be used to eliminate the coefficients of in the third equation:
![\[\begin{split} x_1+x_2+x_3&=3\\ 0+1x_2+2x_3&=-2\\ 0+0-2x_3&=17\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-4311d86b393b12686dadf5143899770d_l3.png "Rendered by QuickLaTeX.com")
It will also be used to eliminate the coefficients of in the first equation:
![\[\begin{split} x_1+0-x_3&=5\\ 0+1x_2+2x_3&=-2\\ 0+0-2x_3&=17\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ffd84e0f9d5dba79de860f7d35b57dac_l3.png "Rendered by QuickLaTeX.com")
The third pivot element will now be normalized:
![\[\begin{split} x_1+0-x_3&=5\\ 0+1x_2+2x_3&=-2\\ 0+0+x_3&=-\frac{17}{2}\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-eeec25bd4baba1ea37edcb609a723d27_l3.png "Rendered by QuickLaTeX.com")
The third row is used to eliminate the coefficients of in the second and first equations:
![\[\begin{split} x_1+0+0&=-\frac{7}{2}\\ 0+x_2+0&=15\\ 0+0+x_3&=-\frac{17}{2}\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-923cb7923be082940c7a760487bd4a13_l3.png "Rendered by QuickLaTeX.com")
The right hand side is the required solution! In matrix form the following are essentially the steps above:
![\[ \left(\begin{array}{ccc|c}2&2&2&6\\2&3&4&4\\-1&2&3&8\end{array}\right)\Rightarrow \left(\begin{array}{ccc|c}1&1&1&3\\0&1&2&-2\\0&3&4&11\end{array}\right) \Rightarrow \left(\begin{array}{ccc|c}1&0&-1&5\\0&1&2&-2\\0&0&-2&17\end{array}\right) \Rightarrow \left(\begin{array}{ccc|c}1&0&0&-\frac{7}{2}\\0&1&0&15\\0&0&1&-\frac{17}{2}\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-b25a4e221b4b4e6cce8f96cd7e95eb1e_l3.png "Rendered by QuickLaTeX.com")
The same issue of zero pivot applies to this method and another step of “pivoting” could be added to ensure no zero pivot is found in the matrix.
View Mathematica CodeGJElimination[A_, b_] :=
(n = Length[A];
G = Transpose[Insert[Transpose[A], b, n + 1]];
For[k = 1, k <= n,
k++, (G[[k]] = G[[k]]/G[[k, k]];
Do[G[[i]] = G[[i]] - G[[i, k]]*G[[k]], {i, 1, k - 1}];
Do[G[[i]] = G[[i]] - G[[i, k]]*G[[k]], {i, k + 1, n}])];
x = G[[All, n + 1]])
A = {{1, 2, 3, 5}, {2, 0, 1, 4}, {1, 2, 2, 5}, {4, 3, 2, 2}};
b = {-4, 8, 0, 10};
GJElimination[A, b]
LU Decomposition
Another method that is comparable in efficiency and speed to the Gauss elimination methods stated above is the LU decomposition. It was implied when the Gauss elimination method was introduced that if a linear system of equations is such that the matrix is an upper triangular matrix, then the system can be solved directly using backward substitution. Similarly, if a linear system of equations is such that the matrix is a lower triangular matrix, then the system can be solved directly using forward substitution. The following two examples illustrate this.
Solving Lower Triangular Systems
Consider the linear system defined as:
![\[\begin{split} 5x_1+0+0&=15\\ 2x_1+3x_2+0&=6\\ 4x_1+3x_2+2x_3&=2\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-6345196498eaaa16b5ceba68e94043a6_l3.png "Rendered by QuickLaTeX.com")
which in matrix form has the form:
![\[ \left(\begin{matrix}5&0&0\\2&3&0\\4&3&2\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{array}{c}15\\6\\2\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-75217d2f8466d01f0e270028bc0fb266_l3.png "Rendered by QuickLaTeX.com")
The matrix is a lower triangular matrix. The system can be solved by forward substitution. Namely, the first equation gives  . The second equation gives:
. The second equation gives:  . The third equation gives:
. The third equation gives:  . Forward substitution can be programmed in a very fast and efficient manner. Consider the following system:
. Forward substitution can be programmed in a very fast and efficient manner. Consider the following system:
![\[ \left(\begin{matrix}L_{11}&0&0&\cdots&0\\L_{21}&L_{22}&0&\cdots&0\\L_{31}&L_{32}&L_{33}&\cdots&0\\\vdots&\vdots&\vdots&&\vdots\\L_{n1}&L_{n2}&L_{n3}&\cdots&L_{nn}\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\\\vdots\\x_n\end{array}\right)= \left(\begin{array}{c}b_1\\b_2\\b_3\\\vdots\\b_n\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-05972f6e6d67d7a54c7e8fe211f2dcb3_l3.png "Rendered by QuickLaTeX.com")
Therefore:
![\[\begin{split} x_1&=\frac{b_1}{L_{11}}\\ x_2&=\frac{b_2-L_{21}x_1}{L_{22}}\\ x_3&=\frac{b_3-L_{31}x_1-L_{32}x_2}{L_{33}}\\ &\vdots\\ x_n&=\frac{b_n-\sum_{j=1}^{n-1}L_{nj}x_j}{L_{nn}} \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ec231c1e50bb94fc8e780defa3840301_l3.png "Rendered by QuickLaTeX.com")
This can be written in the following simple form with starting at  to :
to :
![\[ x_i=\frac{b_i - \sum_{j=1}^{i-1}L_{ij}x_j}{L_{ii}} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-6654d0e02e2a27bd2e69807887924ecb_l3.png "Rendered by QuickLaTeX.com")
Solving Upper Triangular Systems
Similarly, consider the linear system defined as:
![\[\begin{split} 2x_1+3x_2+4x_3&=2\\ 0+3x_2+2x_3&=6\\ 0+0+5x_3&=15 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-975573cabbbc402739015d2c21632e8a_l3.png "Rendered by QuickLaTeX.com")
which in matrix form has the form:
![\[ \left(\begin{matrix}2&3&4\\0&3&2\\0&0&5\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{array}{c}2\\6\\15\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-e5aaba1d5bbafb3e76bd284a5da6629c_l3.png "Rendered by QuickLaTeX.com")
The matrix is an upper triangular matrix. The system can be solved by backward substitution. Namely, the third equation gives  . The second equation gives:
. The second equation gives:  . The first equation gives:
. The first equation gives:  . Backward substitution can be easily programmed in a very fast and efficient manner. Consider the following system:
. Backward substitution can be easily programmed in a very fast and efficient manner. Consider the following system:
![\[ \left(\begin{matrix}U_{11}&U_{12}&U_{13}&\cdots&U_{1n}\\0&U_{22}&U_{23}&\cdots&U_{2n}\\0&0&U_{33}&\cdots&U_{3n}\\\vdots&\vdots&\vdots&&\vdots\\0&0&0&\cdots&U_{nn}\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\\\vdots\\x_n\end{array}\right)= \left(\begin{array}{c}b_1\\b_2\\b_3\\\vdots\\b_n\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-d383550265b61db71dcdf770b6221a9b_l3.png "Rendered by QuickLaTeX.com")
Therefore:
![\[\begin{split} x_n&=\frac{b_n}{U_{nn}}\\ &\vdots\\ x_{3}&=\frac{b_3-\sum_{j=4}^nU_{3j}x_j}{U_{33}}\\ x_{2}&=\frac{b_2-\sum_{j=3}^nU_{2j}x_j}{U_{22}}\\ x_1&=\frac{b_1-\sum_{j=2}^{n}U_{1j}x_j}{U_{11}} \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-20b98b0f1b1807cd4cf585ad40cce3ec_l3.png "Rendered by QuickLaTeX.com")
This can be written in the following simple form with starting at  and decreasing to
and decreasing to  :
:
![\[ x_i=\frac{b_i - \sum_{j=i+1}^{n}U_{ij}x_j}{U_{ii}} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-77a5c81abfb2a8e0aedcb121030e57be_l3.png "Rendered by QuickLaTeX.com")
LU Decomposition Example
We will first introduce the LU decomposition using an example, consider the system defined as:
![\[ \left(\begin{matrix}2&1&1\\5&2&2\\4&3&2\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{array}{c}5\\6\\3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-07120c3d30c9227b24fc792c3d89d2ea_l3.png "Rendered by QuickLaTeX.com")
Without explaining how at this point, we can decompose the matrix as the multiplication of two matrices  where
where  is a lower triangular matrix and
is a lower triangular matrix and  is an upper triangular matrix. For this particular example, and have the forms:
is an upper triangular matrix. For this particular example, and have the forms:
![\[ L=\left(\begin{matrix}1&0&0\\2.5&1&0\\2&-2&1\end{matrix}\right)\qquad U=\left(\begin{matrix}2&1&1\\0&-0.5&-0.5\\0&0&-1\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-8c7a365df1cd59363089f06e1ce5b2ef_l3.png "Rendered by QuickLaTeX.com")
The reader should verify that indeed . The linear system of equations can then be written as:
![\[ \left(\begin{matrix}1&0&0\\2.5&1&0\\2&-2&1\end{matrix}\right)\left(\begin{matrix}2&1&1\\0&-0.5&-0.5\\0&0&-1\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{array}{c}5\\6\\3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-7e984d8d76697720c7d3cafd837d214a_l3.png "Rendered by QuickLaTeX.com")
The above system can be solved quickly as follows. In the equation  , set
, set  , then
, then  . Since is a lower triangular matrix, we can solve for
. Since is a lower triangular matrix, we can solve for  easily. Then, since
easily. Then, since  and is an upper triangular matrix, we can solve for easily. The equation has the form:
and is an upper triangular matrix, we can solve for easily. The equation has the form:
![\[ \left(\begin{matrix}1&0&0\\2.5&1&0\\2&-2&1\end{matrix}\right)\left(\begin{array}{c}y_1\\y_2\\y_3\end{array}\right)=\left(\begin{array}{c}5\\6\\3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ec736b050a19882413cb08bdb32f3928_l3.png "Rendered by QuickLaTeX.com")
The above system can be solved using forward substitution. Therefore  . The second equation yields:
. The second equation yields:  . The third equation yields:
. The third equation yields:  . We can now solve as follows:
. We can now solve as follows:
![\[ \left(\begin{matrix}2&1&1\\0&-0.5&-0.5\\0&0&-1\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{array}{c}y_1\\y_2\\y_3\end{array}\right)=\left(\begin{array}{c}5\\-6.5\\-20\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-9fdcb5610147ef523af72858825d9384_l3.png "Rendered by QuickLaTeX.com")
This system can be solved using backward substitution. The third equation yields  . The second equation yields
. The second equation yields  . The third equation yields
. The third equation yields  . This example implies that if the matrix can be decomposed such that where is a lower triangular matrix and is an upper triangular matrix, then the system can be easily solved using forward and backward substitution. It turns out that such decomposition always exists provided that the rows of the matrix are properly ordered (by that we mean there are no zero pivots during the Gauss elimination step).
. This example implies that if the matrix can be decomposed such that where is a lower triangular matrix and is an upper triangular matrix, then the system can be easily solved using forward and backward substitution. It turns out that such decomposition always exists provided that the rows of the matrix are properly ordered (by that we mean there are no zero pivots during the Gauss elimination step).
Formal Representation
The following is a more formal representation of the method. Let be a linear system of equations. Let be an LU decomposition for with being a lower triangular matrix and being an upper triangular matrix. Then:  . Set
. Set  , then . The elements of the vector can be solved using forward substitution as explained above. Then, the system can be solved using backward substitution as explained above.
, then . The elements of the vector can be solved using forward substitution as explained above. Then, the system can be solved using backward substitution as explained above.
LU Decomposition Algorithm
There are various algorithms to find the decomposition  . Mathematica has a built-in function to find the LU decomposition called “LUDecomposition”. Here we present the most common algorithm. In the first step, using Gauss elimination, the matrix is turned into an upper triangular matrix which is the matrix . The matrix has values of 1 in the diagonal entries. The entries
. Mathematica has a built-in function to find the LU decomposition called “LUDecomposition”. Here we present the most common algorithm. In the first step, using Gauss elimination, the matrix is turned into an upper triangular matrix which is the matrix . The matrix has values of 1 in the diagonal entries. The entries  that are below the diagonals are such that
that are below the diagonals are such that  negative the factor that was used to reduce row using the pivot row
negative the factor that was used to reduce row using the pivot row  during the Gauss elimination step. The following example illustrates the process. Consider the matrix
during the Gauss elimination step. The following example illustrates the process. Consider the matrix
![\[ \left(\begin{matrix}2&1&1\\5&2&2\\4&3&2\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-c3b840456f7dc50f9aeb6c9357718320_l3.png "Rendered by QuickLaTeX.com")
To find both and we will write the identity matrix on the left and the matrix on the right:
![\[ \left(\begin{matrix}1&0&0\\0&1&0\\0&0&1\end{matrix}\right) \qquad \left(\begin{matrix}2&1&1\\5&2&2\\4&3&2\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-b1f06bab2e3eb0c428b2b7e42dc9e303_l3.png "Rendered by QuickLaTeX.com")
Gauss elimination is then used to eliminate the coefficient  by multiplying row 1 by
by multiplying row 1 by  and then adding it to row 2. Then, the coefficient
and then adding it to row 2. Then, the coefficient 
![\[ \left(\begin{matrix}1&0&0\\2.5&1&0\\0&0&1\end{matrix}\right) \qquad \left(\begin{matrix}2&1&1\\0&-0.5&-0.5\\4&3&2\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-70136e176d7c68230c7073ceb59e6a88_l3.png "Rendered by QuickLaTeX.com")
Gauss elimination is then used to eliminate the coefficient  by multiplying row 1 by
by multiplying row 1 by  and then adding it to row 3. Then, the coefficient
and then adding it to row 3. Then, the coefficient 
![\[ \left(\begin{matrix}1&0&0\\2.5&1&0\\2&0&1\end{matrix}\right) \qquad \left(\begin{matrix}2&1&1\\0&-0.5&-0.5\\0&1&0\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-04c49d2e457049f8334b1c856b1aeb2d_l3.png "Rendered by QuickLaTeX.com")
Gauss elimination is then used to eliminate the coefficient  by multiplying row 2 by
by multiplying row 2 by  and then adding it to row 3. Then, the coefficient
and then adding it to row 3. Then, the coefficient 
![\[ \left(\begin{matrix}1&0&0\\2.5&1&0\\2&-2&1\end{matrix}\right) \qquad \left(\begin{matrix}2&1&1\\0&-0.5&-0.5\\0&0&-1\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-443f8d7c483beb22755e252b2e36ce31_l3.png "Rendered by QuickLaTeX.com")
The matrix on the left hand side is and the one on the right hand side is .
Programming the Method
Programming the LU decomposition method requires three steps. In the first one, the Gauss elimination is used to create the and matrices. Then, forward substitution is used to solve for the vector in . Then, backward substitution is used to solve for the vector in . The following code has two procedures, the first one takes the matrix and produces the two matrices and . The second procedure utilizes the first procedure to produce and and then uses the backward and forward substitutions to find the vectors and then .
LU[A_] :=
(n = Length[A];
L = IdentityMatrix[n];
U = A;
For[k = 1, k <= n, k++,
Do[L[[i, k]] = U[[i, k]]/U[[k, k]];U[[i]] = U[[i]] - U[[i, k]]/U[[k, k]]*U[[k]], {i, k + 1, n}]];
{L, U})
LUAB[A_, b_] :=
(n = Length[A];
L = LU[A][[1]];
U = LU[A][[2]];
y = Table[0, {i, 1, n}];
x = Table[0, {i, 1, n}];
For[i = 1, i <= n,i = i + 1, (BB = 0; Do[BB = L[[i, l]]*y[[l]] + BB, {l, 1, i - 1}]; y[[i]] = (b[[i]] - BB)/L[[i, i]])];
For[i = n, i >= 1, i = i - 1, (BB = 0; Do[BB = U[[i, l]]*x[[l]] + BB, {l, i + 1, n}]; x[[i]] = (y[[i]] - BB)/U[[i, i]])];
x)
A = {{1, 2, 3, 5}, {2, 0, 1, 4}, {1, 2, 2, 5}, {4, 3, 2, 2}};
b = {-4, 8, 0, 10};
LUAB[A, b]
Comparison with Previous Methods
In comparison to the naive Gauss elimination method, this method reduces the computations in the forward elimination step by conducting the forward elimination step on the matrix without adding the vector . However, it adds another step which is the forward substitution step described above. The advantage of this method is that no manipulations are done on the vector . So, if multiple solutions corresponding to multiple possible values of the vector are sought, then this method could be faster than the Gauss elimination methods.
Cholesky Factorization for Positive Definite Symmetric Matrices
Positive definite symmetric matrices appear naturally in many engineering problems. In particular, the stiffness matrices of elastic structures that appear in the stiffness method and the finite element analysis method for structural engineering applications are positive definite symmetric matrices. Positive definite symmetric matrices, as shown in this section have positive eigenvalues and so working with them can be very easy. Also, being symmetric, only one half of the off diagonal components need to be stored which reduces the computational time significantly. The Cholesky Factorization is a particular type of LU decomposition that can be applied to symmetric matrices. In particular, a positive definite symmetric matrix can be decomposed such that:
![\[ A=LL^T=U^TU \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-0129cf34ff6c644b5709584ffb0cd9ed_l3.png "Rendered by QuickLaTeX.com")
Where  is a lower triangular matrix and its transpose
is a lower triangular matrix and its transpose  is an upper triangular matrix. For example, the following symmetric matrix is positive definite (because all its eigenvalues when calculated are positive):
is an upper triangular matrix. For example, the following symmetric matrix is positive definite (because all its eigenvalues when calculated are positive):
![\[ A=\left(\begin{matrix}1&3&2\\3&13&8\\2&8&6\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-97c99f63ce795281b1716092f9853aee_l3.png "Rendered by QuickLaTeX.com")
admits the following decomposition  :
:
![\[ \left(\begin{matrix}1&3&2\\3&13&8\\2&8&6\end{matrix}\right)=\left(\begin{matrix}1&0&0\\3&2&0\\2&1&1\end{matrix}\right)\left(\begin{matrix}1&3&2\\0&2&1\\0&0&1\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-749a99fa512602169c0b6ad66e102cbf_l3.png "Rendered by QuickLaTeX.com")
This decomposition is similar to the LU decomposition and if a linear system is such that is positive definite, then the Cholesky decomposition enables the quick calculation of and then the backward and forward substitution can be used to solve the system (as shown in the LU decomposition section). The factorization can be found by noticing that the diagonal entry of admits the following:
![\[ A_{ii}=\sum_{k=1}^nU_{ki}U_{ki}=\sum_{k=1}^iU_{ki}U_{ki}=\sum_{k=1}^{i-1}U_{ki}U_{ki}+U_{ii}^2 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-e5394471c808ca73402695a19eb73e72_l3.png "Rendered by QuickLaTeX.com")
where the fact that  whenever
whenever  was used. Therefore:
was used. Therefore:
(1) 
On the other hand, an off diagonal component  admits the following:
admits the following:
![\[ A_{ij}=\sum_{k=1}^nU_{ki}U_{kj}=\sum_{k=1}^iU_{ki}U_{kj}=\sum_{k=1}^{i-1}U_{ki}U_{kj}+U_{ii}U_{ij} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-3e8576b9f3d5ae559d859e6de15e7a1d_l3.png "Rendered by QuickLaTeX.com")
where again, the fact that whenever was used. Therefore:
(2) 
Notice that for the factorization to work, we can’t have negative values for  or zero values for
or zero values for  which is guaranteed not to occur because is positive definite.
which is guaranteed not to occur because is positive definite.
Programming
Equations 1 and 2 can be programmed by first setting , then iterating from 2 to . Then, setting  and iterating from 3 to and so on. As an illustration, we will apply the algorithm for
and iterating from 3 to and so on. As an illustration, we will apply the algorithm for
![\[ A=\left(\begin{matrix}1&3&2\\3&13&8\\2&8&6\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-e463594d604f9282056738e7fd594db9_l3.png "Rendered by QuickLaTeX.com")
Setting in Equation 1 yields:
![\[ U_{11}=\sqrt{A_{11}}=\sqrt{1}=1 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-c19fe2a089649af4295936b61cdaff8a_l3.png "Rendered by QuickLaTeX.com")
Iterating from 2 to 3 in Equation 2 yields:
![\[ U_{12}=\frac{A_{12}}{U_{11}}=3\qquad U_{13}=\frac{A_{13}}{U_{11}}=2 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-571d6eb99d2b37dfa32ebd44377e4d8a_l3.png "Rendered by QuickLaTeX.com")
Setting in Equation 1 yields:
![\[ U_{22}=\sqrt{A_{22}-U_{12}U_{12}}=\sqrt{13-9}=2 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-19ea2530fcd289dafa114df41897e12d_l3.png "Rendered by QuickLaTeX.com")
Iterating from 3 to 3 in Equation 2 yields:
![\[ U_{23}=\frac{A_{23}-U_{12}U_{13}}{U_{22}}=\frac{8-3\times 2}{2}=1 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-6d6b29b244f6c2c0a4c4c4fc3ff0f3f5_l3.png "Rendered by QuickLaTeX.com")
Finally, setting  in Equation 1 yields:
in Equation 1 yields:
![\[ U_{33}=\sqrt{A_{33}-U_{13}U_{13}-U_{23}U_{23}}=\sqrt{6-4-1}=1 \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-1d5e21fbb85e10eaa5d33bbc8c09645b_l3.png "Rendered by QuickLaTeX.com")
Which yields the following matrix :
![\[ U=\left(\begin{matrix}1&3&2\\0&2&1\\0&0&1\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-02c9159611f5238c6ad90316837c1b86_l3.png "Rendered by QuickLaTeX.com")
The following is the Mathematica code for the algorithm, along with the code to solve a linear system of equations with being positive definite. The algorithm is divided into two procedures. The first procedure calculates the Cholesky Decompsition of a matrix and the second procedure uses and  for backward and forward substitution as described in the LU decomposition. It should be noted that in general the Cholesky Decomposition should be much more efficient than the LU decomposition for positive definite symmetric matrices. However, the code below will need to be optimized to achieve that.
for backward and forward substitution as described in the LU decomposition. It should be noted that in general the Cholesky Decomposition should be much more efficient than the LU decomposition for positive definite symmetric matrices. However, the code below will need to be optimized to achieve that.
CD[A_] :=
(n = Length[A];
U = Table[0, {i, 1, n}, {j, 1, n}];
Do[U[[i, i]] = Sqrt[A[[i, i]] - Sum[U[[k, i]] U[[k, i]], {k, 1, i - 1}]];U[[i, j]] = (A[[i, j]] - Sum[U[[k, i]] U[[k, j]], {k, 1, i - 1}])/U[[i, i]], {i, 1, n}, {j, i, n}];
U)
CDAB[A_, b_] :=
(n = Length[A];
U = CD[A];
L = Transpose[U];
y = Table[0, {i, 1, n}];
x = Table[0, {i, 1, n}];
For[i = 1, i <= n,i = i + 1, (BB = 0; Do[BB = L[[i, l]]*y[[l]] + BB, {l, 1, i - 1}]; y[[i]] = (b[[i]] - BB)/L[[i, i]])];
For[i = n, i >= 1, i = i - 1, (BB = 0; Do[BB = U[[i, l]]*x[[l]] + BB, {l, i + 1, n}]; x[[i]] = (y[[i]] - BB)/U[[i, i]])];
x)
A = {{39, 25, 36, 26}, {25, 21, 24, 18}, {36, 24, 34, 24}, {26, 18, 24, 33}};
b = {-196, 392, 0, 490}
N[CDAB[A, b]]
FullSimplify[CDAB[A, b]]
The above code relies on using the “Sum” command in Mathematica which is not very efficient. The following code is more efficient and uses the “Do” command for the sum function:
View Mathematica Code
CD[A_] :=
(n = Length[A];
U = Table[0, {i, 1, n}, {j, 1, n}];
Do[BB = 0; Do[BB = BB + U[[k, i]] U[[k, i]], {k, 1, i - 1}];
U[[i, i]] = Sqrt[A[[i, i]] - BB];
Do[BB = 0; Do[BB = BB + U[[k, i]] U[[k, j]], {k, 1, i - 1}];
U[[i, j]] = (A[[i, j]] - BB)/U[[i, i]], {j, i + 1, n}], {i, 1, n}];
U)
CDAB[A_, b_] := (n = Length[A];
U = CD[A];
L = Transpose[U];
y = Table[0, {i, 1, n}];
x = Table[0, {i, 1, n}];
For[i = 1, i <= n, i = i + 1, (BB = 0; Do[BB = L[[i, l]]*y[[l]] + BB, {l, 1, i - 1}]; y[[i]] = (b[[i]] - BB)/L[[i, i]])];
For[i = n, i >= 1,i = i - 1, (BB = 0; Do[BB = U[[i, l]]*x[[l]] + BB, {l, i + 1, n}]; x[[i]] = (y[[i]] - BB)/U[[i, i]])];
x)
A = {{39, 25, 36, 26}, {25, 21, 24, 18}, {36, 24, 34, 24}, {26, 18, 24, 33}};
b = {-196, 392, 0, 490}
N[CDAB[A, b]]
FullSimplify[CDAB[A, b]]
Mathematica
Mathematica can be used to calculate the Cholesky Factorization using the function “CholeskyDecomposition[]” which outputs the matrix in the decomposition .
View Mathematica Code
A={{1,3,2},{3,13,8},{2,8,6}}
U=CholeskyDecomposition[A]
Transpose[U].U//MatrixForm
Iterative Methods to Solve Linear Systems
In the previous section, we introduced methods that produced an exact solution for the determined linear system . These methods relied on exactly solving the set of equations at hand. There are other “numerical techniques” that involve iterative methods that are similar to the iterative methods shown in the root finding methods section. When is relatively large, and when the matrix is banded, then these methods might become more efficient than the traditional methods above.
The Jacobi Method
The Jacobi method is named after Carl Gustav Jacob Jacobi. The method is akin to the fixed-point iteration method in single root finding described before. First notice that a linear system of size can be written as:
![\[ \left(\begin{matrix}a_{11}&a_{12}&\cdots&a_{1n}\\a_{21}&a_{22}&\cdots&a_{2n}\\\vdots&\vdots&\vdots&\vdots\\a_{n1}&a_{n2}&\cdots&a_{nn}\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\\vdots\\x_n\end{array}\right)=\left(\begin{array}{c}b_1\\b_2\\\vdots\\b_n\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-d9388445e27140d2847757ea871998f7_l3.png "Rendered by QuickLaTeX.com")
The left hand side can be decomposed as follows:
![\[ \left(\begin{matrix}0&a_{12}&\cdots&a_{1n}\\a_{21}&0&\cdots&a_{2n}\\\vdots&\vdots&\vdots&\vdots\\a_{n1}&a_{n2}&\cdots&0\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\\vdots\\x_n\end{array}\right)+\left(\begin{matrix}a_{11}&0&\cdots&0\\0&a_{22}&\cdots&0\\\vdots&\vdots&\vdots&\vdots\\0&0&\cdots&a_{nn}\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\\vdots\\x_n\end{array}\right)=\left(\begin{array}{c}b_1\\b_2\\\vdots\\b_n\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-9dc87f8d6c32061e6c99572068f23238_l3.png "Rendered by QuickLaTeX.com")
Effectively, we have separated into two additive matrices:  where
where  has zero entries in the diagonal components and
has zero entries in the diagonal components and  is a diagonal matrix. If we start with nonzero diagonal components for , then is a diagonal matrix with nonzero entries in the diagonal and can easily be inverted and its inverse is:
is a diagonal matrix. If we start with nonzero diagonal components for , then is a diagonal matrix with nonzero entries in the diagonal and can easily be inverted and its inverse is:
![\[ D^{-1}=\left(\begin{matrix}\frac{1}{a_{11}}&0&\cdots&0\\0&\frac{1}{a_{22}}&\cdots&0\\\vdots&\vdots&\vdots&\vdots\\0&0&\cdots&\frac{1}{a_{nn}}\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-1d598070594a2a38655134217af8eee1_l3.png "Rendered by QuickLaTeX.com")
Therefore:
![\[ Rx+Dx=b\Rightarrow x=D^{-1}(b-Rx) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-0d2fbe8962333c75539fc6b58c92920a_l3.png "Rendered by QuickLaTeX.com")
This form is similar to the fixed-point iteration method. By assuming initial guesses for the components of the vector and substituting in the right hand side, then a new estimate for the components of can be computed. In addition to having non-zero diagonal components for , there are other requirements for the matrix  for this method to converge to a proper solution which are beyond the scope of these notes. One fact that is useful is that this method will converge if the diagonal components of are large compared to the rest of the matrix components. The criteria for stopping this algorithm will be based on the size or the norm of the difference between the vector in each iteration. For this, we can use the Euclidean norm. So, if the components of the vector after iteration are
for this method to converge to a proper solution which are beyond the scope of these notes. One fact that is useful is that this method will converge if the diagonal components of are large compared to the rest of the matrix components. The criteria for stopping this algorithm will be based on the size or the norm of the difference between the vector in each iteration. For this, we can use the Euclidean norm. So, if the components of the vector after iteration are  , and if after iteration the components are:
, and if after iteration the components are:  , then, the stopping criterion would be:
, then, the stopping criterion would be:
![\[ \frac{\|x^{(i+1)}-x^{(i)}\|}{\|x^{(i+1)}\|}\leq \varepsilon_s \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-9cbcb16ed112d7a289b8e6e33d495bcf_l3.png "Rendered by QuickLaTeX.com")
where
![\[\begin{split} \|x^{(i+1)}-x^{(i)}\|&=\sqrt{(x_1^{(i+1)}-x_1^{(i)})^2+(x_2^{(i+1)}-x_2^{(i)})^2+\cdots+(x_n^{(i+1)}-x_n^{(i)})^2}\\ \|x^{(i+1)}\|&=\sqrt{(x_1^{(i+1)})^2+(x_2^{(i+1)})^2+\cdots+(x_n^{(i+1)})^2}\\ \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-f500d45c89c156aa0adbac55267bfee1_l3.png "Rendered by QuickLaTeX.com")
Note that any other norm function can work as well.
Example
Consider the system defined as:
![\[ \left(\begin{matrix}3&-0.1&-0.2\\0.1&7&-0.3\\0.3&-0.2&10\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{array}{c}7.85\\-19.3\\71.4\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-0b7c7cb1f7cba7417118f7066c87c4d1_l3.png "Rendered by QuickLaTeX.com")
The Jacobi method with a stopping criterion of  will be used. First the system is rearranged to the form:
will be used. First the system is rearranged to the form:
![\[ \left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{matrix}\frac{1}{3}&0&0\\0&\frac{1}{7}&0\\0&0&\frac{1}{10}\end{matrix}\right)\left(\left(\begin{array}{c}7.85\\-19.3\\71.4\end{array}\right)-\left(\begin{matrix}0&-0.1&-0.2\\0.1&0&-0.3\\0.3&-0.2&0\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-5792832e3968106d15535ac49234fab9_l3.png "Rendered by QuickLaTeX.com")
Then, the initial guesses for the components  are used to calculate the new estimates:
are used to calculate the new estimates:
![\[ x^{(1)}=\left(\begin{array}{c}2.717\\-2.7286\\7.13\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-28d79d72af340e86a632379814b350d7_l3.png "Rendered by QuickLaTeX.com")
The relative approximate error in this case is
![\[ \varepsilon_r=\frac{\sqrt{(2.717-1)^2+(-2.7286-1)^2+(7.13-1)^2}}{\sqrt{2.717^2+(-2.7286)^2+7.13^2}}=0.91>\varepsilon_s \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-8546571599cac3d1a9b0a5b60b339996_l3.png "Rendered by QuickLaTeX.com")
The next iteration:
![\[ x^{(2)}=\left(\begin{array}{c}3.00105\\-2.49038\\7.00393\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-a658b2d57506803391625079cd27bb6d_l3.png "Rendered by QuickLaTeX.com")
The relative approximate error in this case is
![\[ \varepsilon_r=\frac{\sqrt{(3.00105-2.717)^2+(-2.49038+2.7286)^2+(7.00393-7.13)^2}}{\sqrt{3.00105^2+(-2.49038)^2+7.00393^2}}=0.0489>\varepsilon_s \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-8ed463d027eaad37f32c97d623128687_l3.png "Rendered by QuickLaTeX.com")
The third iteration:
![\[ x^{(3)}=\left(\begin{array}{c}3.00058\\-2.49985\\7.00016\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-5e208269a18008bbc6508545eff0db36_l3.png "Rendered by QuickLaTeX.com")
The relative approximate error in this case is
![\[ \varepsilon_r=\frac{\sqrt{(3.00058-3.00105)^2+(-2.49985+2.49038)^2+(7.00016-7.00393)^2}}{\sqrt{3.00058^2+(-2.49985)^2+7.00016^2}}=0.00127>\varepsilon_s \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-a39ec4953c149882739f32703a316078_l3.png "Rendered by QuickLaTeX.com")
The fourth iteration:
![\[ x^{(4)}=\left(\begin{array}{c}3.00002\\-2.5\\6.99999\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-aad4b870c593e309ce807c0e72a5436e_l3.png "Rendered by QuickLaTeX.com")
The relative approximate error in this case is
![\[ \varepsilon_r=\frac{\sqrt{(3.00002-3.00058)^2+(-2.5+2.49985)^2+(6.99999-7.00016)^2}}{\sqrt{3.00002^2+(-2.5)^2+6.99999^2}}=0.000076 < \varepsilon_s \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-13ff629660b5518c5bf6192378647e0b_l3.png "Rendered by QuickLaTeX.com")
Therefore convergence has been achieved. The exact solution is in fact:
![\[ x=A^{-1}b=\left(\begin{array}{c}3.\\-2.5\\7\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-ac94fca2d860e690d43b2b8c77a3cc42_l3.png "Rendered by QuickLaTeX.com")
Programming the Method
We will use the built-in Norm function for the stopping criteria. In the following code, the procedure “J” takes the matrix , the vector , and the guess to return a new guess for the vector . The maximum number of iterations is 100 and the stopping criteria are either the maximum number of iterations is reached or  :
:
View Mathematica Code
J[A_, b_, x_] := (
n = Length[A];
InvD = Table[0, {i, 1, n}, {j, 1, n}];
R = A;
Do[InvD[[i, i]] = 1/A[[i, i]]; R[[i, i]] = 0, {i, 1, n}];
newx = InvD.(b - R.x)
)
A = {{3, -0.1, -0.2}, {0.1, 7, -0.3}, {0.3, -0.2, 10}}
b = {7.85, -19.3, 71.4}
x = {{1, 1, 1.}};
MaxIter = 100;
ErrorTable = {1};
eps = 0.001;
i = 2;
While[And[i <= MaxIter, Abs[ErrorTable[[i - 1]]] > eps],
xi = J[A, b, x[[i - 1]]]; x = Append[x, xi];
ei = Norm[x[[i]] - x[[i - 1]]]/Norm[x[[i]]];
ErrorTable = Append[ErrorTable, ei]; i++]
x // MatrixForm
ErrorTable // MatrixForm
The Gauss-Seidel Method
The Gauss-Seidel method offers a slight modification to the Jacobi method which can cause it to converge faster. In the Gauss-Seidel method, the system is solved using forward substitution so that each component uses the most recent value obtained for the previous component. This is different from the Jacobi method where all the components in an iteration are calculated based on the previous iteration. First notice that a linear system of size can be written as:
The left hand side can be decomposed as follows:
![\[ \left(\begin{matrix}0&a_{12}&\cdots&a_{1n}\\0&0&\cdots&a_{2n}\\\vdots&\vdots&\vdots&\vdots\\0&0&\cdots&0\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\\vdots\\x_n\end{array}\right)+\left(\begin{matrix}a_{11}&0&\cdots&0\\a_{21}&a_{22}&\cdots&0\\\vdots&\vdots&\vdots&\vdots\\a_{n1}&a_{n2}&\cdots&a_{nn}\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\\vdots\\x_n\end{array}\right)=\left(\begin{array}{c}b_1\\b_2\\\vdots\\b_n\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-55411c761e801e1ee578dd7f2356c706_l3.png "Rendered by QuickLaTeX.com")
Effectively, we have separated into two additive matrices:  where is an upper triangular matrix with zero diagonal components, while is a lower triangular matrix with its diagonal components equal to those of the diagonal components of . If we start with nonzero diagonal components for , then can be used to solve the system using forward substitution:
where is an upper triangular matrix with zero diagonal components, while is a lower triangular matrix with its diagonal components equal to those of the diagonal components of . If we start with nonzero diagonal components for , then can be used to solve the system using forward substitution:
![\[ Ax=b\Rightarrow (U+L)x=b\Rightarrow Lx=b-Ux \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-b9631a0f468520c22181d7b599fc64d7_l3.png "Rendered by QuickLaTeX.com")
the same stopping criterion as in the Jacobi method can be used for the Gauss-Seidel method.
Example
Consider the system defined as:
The Gauss-Seidel method with a stopping criterion of will be used. First the system is rearranged to the form:
![\[ \left(\begin{matrix}3&0&0\\0.1&7&0\\0.3&-0.2&10\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right)=\left(\begin{array}{c}7.85\\-19.3\\71.4\end{array}\right)-\left(\begin{matrix}0&-0.1&-0.2\\0&0&-0.3\\0&0&0\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-be6a9cbb730fdae12b7ac2c9cf0219e3_l3.png "Rendered by QuickLaTeX.com")
Then, the initial guesses for the components are used to calculate the new estimates using forward substitution. Notice that in forward substitution, the value of  uses the value for
uses the value for  and that
and that  uses the values of and :
uses the values of and :
![\[\begin{split} 3x_1^{(1)}=7.85+0.1(1)+0.2(1)\Rightarrow x_1^{(1)}=2.716667\\ 0.1x_1^{(1)}+7x_2^{(1)}=-19.3+0.3(1)\Rightarrow x_2^{(1)}=-2.7531\\ 0.3x_1^{(1)}-0.2x_2^{(1)}+10x_3^{(1)}=71.4\Rightarrow x_3^{(1)}=7.00344 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-1b01a1a740d3a323f660467a218d78e5_l3.png "Rendered by QuickLaTeX.com")
The relative approximate error in this case is
![\[ \varepsilon_r=\frac{\sqrt{(2.716667-1)^2+(-2.7531-1)^2+(7.00344-1)^2}}{\sqrt{2.716667^2+(-2.7531)^2+7.00344^2}}=0.91>\varepsilon_s \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-bc2645b414cf53b452ca5f41068c8b16_l3.png "Rendered by QuickLaTeX.com")
For iteration 2:
![\[\begin{split} 3x_1^{(2)}=7.85+0.1(-2.7531)+0.2(7.00344)\Rightarrow x_1^{(2)}=2.99179\\ 0.1x_1^{(2)}+7x_2^{(2)}=-19.3+0.3(7.00344)\Rightarrow x_2^{(2)}=-2.49974\\ 0.3x_1^{(2)}-0.2x_2^{(2)}+10x_3^{(2)}=71.4\Rightarrow x_3^{(2)}=7.00025 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-3570325174bf16f484dbc18ae3394fd0_l3.png "Rendered by QuickLaTeX.com")
The relative approximate error in this case is
![\[ \varepsilon_r=\frac{\sqrt{(2.99179-2.716667)^2+(-2.49974+2.7531)^2+(7.00025-7.00344)^2}}{\sqrt{2.99179^2+(-2.49974)^2+7.00025^2}}=0.047>\varepsilon_s \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-899e3147607e39eb2cb000e86fec6130_l3.png "Rendered by QuickLaTeX.com")
For iteration 3:
![\[\begin{split} 3x_1^{(3)}=7.85+0.1(-2.49974)+0.2(7.00025)\Rightarrow x_1^{(3)}=3.00003\\ 0.1x_1^{(3)}+7x_2^{(3)}=-19.3+0.3(7.00025)\Rightarrow x_2^{(3)}=-2.49999\\ 0.3x_1^{(3)}-0.2x_2^{(3)}+10x_3^{(3)}=71.4\Rightarrow x_3^{(3)}=7. \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-7c69945e57e0024fc8f8e0313669bba3_l3.png "Rendered by QuickLaTeX.com")
The relative approximate error in this case is
![\[ \varepsilon_r=\frac{\sqrt{(3.00003-2.99179)^2+(-2.49999+2.49974)^2+(7.-7.00025)^2}}{\sqrt{3.00003^2+(-2.49999)^2+7.^2}}=0.00103>\varepsilon_s \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-972e427bbd1d2b1dc9d3352c35b86be6_l3.png "Rendered by QuickLaTeX.com")
And for iteration 4:
![\[\begin{split} 3x_1^{(4)}=7.85+0.1(-2.49999)+0.2(7)\Rightarrow x_1^{(4)}=3.\\ 0.1x_1^{(4)}+7x_2^{(4)}=-19.3+0.3(7.)\Rightarrow x_2^{(4)}=-2.5\\ 0.3x_1^{(4)}-0.2x_2^{(4)}+10x_3^{(4)}=71.4\Rightarrow x_3^{(4)}=7. \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-6824eb5ba98c3e092dabd97c21972fd1_l3.png "Rendered by QuickLaTeX.com")
The relative approximate error in this case is
![\[ \varepsilon_r=\frac{\sqrt{(3.-3.00003)^2+(-2.5+2.49999)^2+(7.-7.)^2}}{\sqrt{3^2+(-2.5)^2+7.^2}}=3.4\times 10^{-6}<\varepsilon_s \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-6fb78ec8904f404374c0116c560fdfc7_l3.png "Rendered by QuickLaTeX.com")
Therefore, the system converges after iteration 4 similar to the Jacobi method. It is not obvious in this example, but the Gauss-Seidel method can converge faster than the Jacobi method.
Programming
Using forward substitution in the equation  , then, the component
, then, the component  in iteration can be computed as follows:
in iteration can be computed as follows:
(3) 
The following code utilizes the procedure “GS” that takes a matrix , a vector , and a vector of some guesses to return the new guess for the components of the vector .
View Mathematica Code
GS[A_, b_, x_] :=
(
n = Length[A];
xnew = Table[0, {i, 1, n}];
Do[xnew[[i]] = (b[[i]] - Sum[A[[i, j]] x[[j]], {j, i + 1, n}] - Sum[A[[i, j]] xnew[[j]], {j, 1, i - 1}])/A[[i, i]], {i, 1, n}];
xnew
)
A = {{3, -0.1, -0.2}, {0.1, 7, -0.3}, {0.3, -0.2, 10}}
b = {7.85, -19.3, 71.4}
x = {{1, 1, 1.}};
MaxIter = 100;
ErrorTable = {1};
eps = 0.001;
i = 2;
While[And[i <= MaxIter, Abs[ErrorTable[[i - 1]]] > eps],
xi = GS[A, b, x[[i - 1]]]; x = Append[x, xi];
ei = Norm[x[[i]] - x[[i - 1]]]/Norm[x[[i]]];
ErrorTable = Append[ErrorTable, ei]; i++]
x // MatrixForm
ErrorTable // MatrixForm
Convergence of the Jacobi and the Gauss-Seidel Methods
If the matrix is diagonally dominant, i.e., the values in the diagonal components are large enough, then this is a sufficient condition for the two methods to converge. In particular, if every diagonal component satisfies  , then, the two methods are guaranteed to converge. Generally, when these methods are used, the programmer should first use pivoting (exchanging the rows and/or columns of the matrix ) to ensure the largest possible diagonal components. Use the code above and see what happens after 100 iterations for the following system when the initial guess is
, then, the two methods are guaranteed to converge. Generally, when these methods are used, the programmer should first use pivoting (exchanging the rows and/or columns of the matrix ) to ensure the largest possible diagonal components. Use the code above and see what happens after 100 iterations for the following system when the initial guess is  :
:
![\[ \begin{split} x_1-5x_2&=-4\\ 7x_1-x_2&=6 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-499d95067ab24990b89f9d192e747dbb_l3.png "Rendered by QuickLaTeX.com")
The system above can be manipulated to make it a diagonally dominant system. In this case, the columns are interchanged and so the variables order is reversed:
![\[ \begin{split} -5x_2+x_1&=-4\\ -x_2+7x_1&=6 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-280c333349c5961b4fd353fec191ffe0_l3.png "Rendered by QuickLaTeX.com")
This system will now converge for any choice of an initial guess!
Successive Over-Relaxation (SOR) Method
The successive over-relaxation (SOR) method is another form of the Gauss-Seidel method in which the new estimate at iteration for the component is calculated as the weighted average of the previous estimate  and the estimate using Gauss-Seidel
and the estimate using Gauss-Seidel  :
:
![\[ x_i^{(k+1)}=(1-\omega)x_i^{(k)}+\omega \left(x_i^{(k+1)}\right)_{GS} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-5ff942604195644142b73fe5e1ddb7c4_l3.png "Rendered by QuickLaTeX.com")
where can be obtained using Equation 3 above. The weight factor  is chosen such that
is chosen such that  . If
. If  , then the method is exactly the Gauss-Seidel method. Otherwise, to understand the effect of we will rearrange the above equation to:
, then the method is exactly the Gauss-Seidel method. Otherwise, to understand the effect of we will rearrange the above equation to:
![\[ x_i^{(k+1)}=x_i^{(k)}+\omega \left(\left(x_i^{(k+1)}\right)_{GS}-x_i^{(k)}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-d89d7d91344292a10cbafd6a9a5ee817_l3.png "Rendered by QuickLaTeX.com")
If  , then, the method gives a new estimate that lies somewhere between the old estimate and the Gauss-Seidel estimate, in this case, the algorithm is termed: “under-relaxation” (Figure 1). Under-relaxation can be used to help establish convergence if the method is diverging. If
, then, the method gives a new estimate that lies somewhere between the old estimate and the Gauss-Seidel estimate, in this case, the algorithm is termed: “under-relaxation” (Figure 1). Under-relaxation can be used to help establish convergence if the method is diverging. If  , then the new estimate lies on the extension of the vector joining the old estimate and the Gauss-Seidel estimate and hence the algorithm is termed: “over-relaxation” (Figure 1). Over-relaxation can be used to speed up convergence of a slow-converging process. The following code defines and uses the SOR procedure to calculate the new estimates. Compare with the Gauss-Seidel procedure shown above.
, then the new estimate lies on the extension of the vector joining the old estimate and the Gauss-Seidel estimate and hence the algorithm is termed: “over-relaxation” (Figure 1). Over-relaxation can be used to speed up convergence of a slow-converging process. The following code defines and uses the SOR procedure to calculate the new estimates. Compare with the Gauss-Seidel procedure shown above.
View Mathematica Code
SOR[A_, b_, x_, w_] := (n = Length[A];
xnew = Table[0, {i, 1, n}];
Do[xnew[[i]] = (1 - w)*x[[i]] + w*(b[[i]] - Sum[A[[i, j]] x[[j]], {j, i + 1, n}] - Sum[A[[i, j]] xnew[[j]], {j, 1, i - 1}])/A[[i, i]], {i, 1, n}];
xnew)
A = {{3, -0.1, -0.2}, {0.1, 7, -0.3}, {0.3, -0.2, 10}}
b = {7.85, -19.3, 71.4}
x = {{1, 1, 1.}};
MaxIter = 100;
ErrorTable = {1};
eps = 0.001;
i = 2;
omega=1.1;
While[And[i <= MaxIter, Abs[ErrorTable[[i - 1]]] > eps],
xi = SOR[A, b, x[[i - 1]],omega]; x = Append[x, xi]; ei = Norm[x[[i]] - x[[i - 1]]]/Norm[x[[i]]];
ErrorTable = Append[ErrorTable, ei];
i++]
x // MatrixForm
ErrorTable // MatrixForm
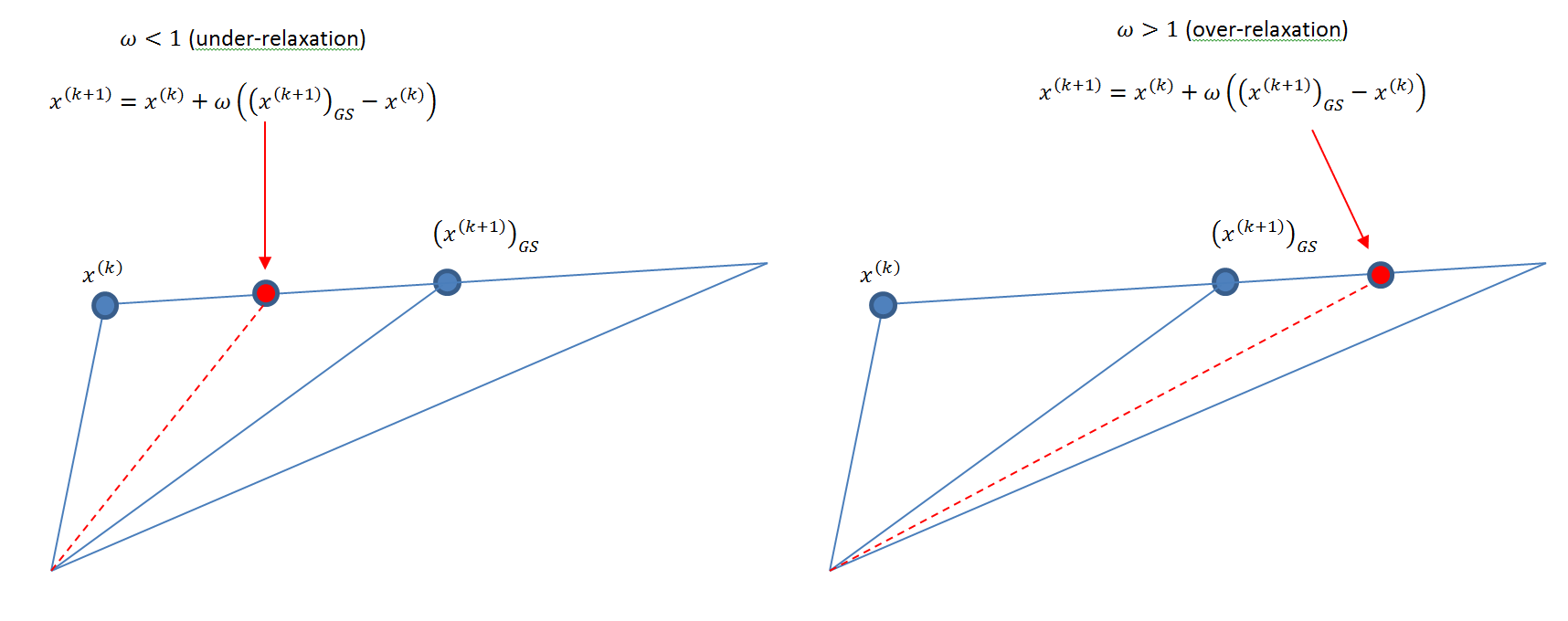
Figure 1. Illustration of under- and over-relaxation methods
Problems
- Create a recursive function in Mathematica that calculates the determinant and compare it with the built-in determinant function. Test your function on matrices in for
 , and
, and  .
. - Use Cramer’s rule to solve the linear system of equations defined as:
![\[ \left(\begin{matrix}1&2&3&7\\2&3&4&8\\-1&2&3&1\\4&5&6&1\end{matrix}\right)\left(\begin{array}{c}x_1\\x_2\\x_3\\x_4\end{array}\right)=\left(\begin{array}{c}3\\2\\4\\7\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-693f995e808faeba235e801070af6ed8_l3.png "Rendered by QuickLaTeX.com")
- Use the naive Gauss elimination method to solve the linear system of equations defined as:
- Use the Cramer’s rule code, the naive Gauss elimination method code, and the Gauss-Jordan elimination method code given above to test how many “simple” equations the algorithm can solve in less than a minute for each method. You can do so by constructing the identity matrix of dimension (using the command IdentityMatrix[n]) and a vector of values 1 of dimension and then running the code. The solution to this should be
 . Repeat for higher values of . If you surround your code with the command Timing[] it should give you an indication of how long the computations are taking. Draw the curve between the size of the system and the timing taken by each method to find the solution. Is the relationship between the time taken to solve the system of equations and the size of the matrix linear or nonlinear?
. Repeat for higher values of . If you surround your code with the command Timing[] it should give you an indication of how long the computations are taking. Draw the curve between the size of the system and the timing taken by each method to find the solution. Is the relationship between the time taken to solve the system of equations and the size of the matrix linear or nonlinear? - Repeat problem 4, however, in this case, use the commands:
A = RandomReal[{-1, 1}, {n, n}]; b = RandomReal[{-1, 1}, n];to generate a matrix
that is with random coefficients between -1 and 1 and a vector with random numbers between -1 and 1. Does this affect the results of the time taken to solve the system as a function of the matrix size and the method used? - Using random numbers similar to the previous problem, draw the curve showing the time taken to solve the system of equations as a function of the matrix size. Compare the LU decomposition, the naive Gauss elimination, and the Gauss-Jordan method. Try to optimize the code of the three methods and see if the generated curves are affected.
- Calculate the Cholesky Decomposition for the following positive definite symmetric matrix:
![\[ A= \left(\begin{matrix}6&15&55\\15&55&225\\55&225&979\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-2274d57f3bb5a3067a9f143adc0133cc_l3.png "Rendered by QuickLaTeX.com")
- Calculate the Cholesky Decomposition for the following positive definite symmetric matrix:
![\[ A= \left(\begin{matrix}8&20&15\\20&80&50\\15&50&60\end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-02ce907d979d76a3d743963bdca9d0ec_l3.png "Rendered by QuickLaTeX.com")
Employ the results to find the solution to the system of equations:
![\[ Ax=b=\left(\begin{array}{c}50\\250\\100\end{array}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-44b073b0d90cd76ee70ccb9e97464c9f_l3.png "Rendered by QuickLaTeX.com")
- Find the LU factorization of the following matrix:
![\[ A=\left(\begin{matrix}10&2&-1\\-3&-6&2\\1&1&5 \end{matrix}\right) \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-7269b95528f4975f03785420e101307e_l3.png "Rendered by QuickLaTeX.com")
Employ the results to find two solutions for the vector
corresponding to the following two linear systems of equations:![\[\begin{split} Ax&=b=\left(\begin{array}{c}12\\18\\-6\end{array}\right)\\ Ax&=b=\left(\begin{array}{c}27\\-61.5\\-21.5\end{array}\right) \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-fe7c9375f2d9781d040841daaabba910_l3.png "Rendered by QuickLaTeX.com")
- Using the “Timing” keyword in Mathematica, compare the efficiency of the Cholesky Decomposition code provided above in comparison the built-in “CholeskyDecomposition” function in Mathematica by finding the decomposition for the identity matrix of size . Can you produce a more efficient version of the provided code?
- Use the “CholeskyDecomposition” built-in function in Mathematica to produce a code to utilize the Cholesky Decomposition method to solve the linear system when is positive definite symmetric matrix. Compare with the Gauss elimination, the Gauss-Jordan elimination and the LU decomposition methods when solving the simple system of equations
 where is a vector whose components are all equal to 1. Similar to problem 4, draw the relationship showing the timing as a function of the size of the matrix .
where is a vector whose components are all equal to 1. Similar to problem 4, draw the relationship showing the timing as a function of the size of the matrix . - Use Mathematica to program the Jacobi method such that the code would re-arrange the rows of the matrix to ensure that the diagonal entries are all non-zero.
- Compare the Jacobi method and the Gauss elimination method to solve the simple system of equations where is a vector whose components are all equal to 5. Similar to problem 4, draw the relationship showing the timing as a function of the size of the matrix . What do you notice about the Jacobi method in this case?
- Use the Gauss-Seidel method to find a solution to the following system after converting it into a diagonally dominant system:
![\[\begin{split} x_1+3x_2-x_3&=5\\ 3x_1-x_2&=5\\ x_2+2x_3&=1 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-49a331a344eee266587883cd8a956353_l3.png "Rendered by QuickLaTeX.com")
- The following system is not diagonally dominant. Check whether the Jacobi and Gauss-Seidel methods converge or not using an initial guess of the zero vector.
![\[\begin{split} 4x_1+2x_2-2x_3&=0\\ x_1-3x_2-x_3&=7\\ 3x_1-x_2+4x_3&=5 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-586aeddbbce44c20ad90d5b9ef5e80da_l3.png "Rendered by QuickLaTeX.com")
- Assuming a stopping criterion of
 , find the optimal value of in the SOR method producing the fastest convergence in finding the solution to the following system. Compare with the Gauss-Seidel method.
, find the optimal value of in the SOR method producing the fastest convergence in finding the solution to the following system. Compare with the Gauss-Seidel method.
![\[\begin{split} 4x_1+3x_2&=24\\ 3x_1+4x_2-x_3&=30\\ -x_2+4x_3&=-24 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-bc795697eac3a7bdcee340c98b1582d7_l3.png "Rendered by QuickLaTeX.com")
- Use the Gauss-Seidel method with
 to solve the following system of linear equations:
to solve the following system of linear equations:
![\[\begin{split} 15c_1-3c_2-c_3=3800\\ -3c_1+18c_2-6c_3=1200\\ -4c_1-c_2+12c_3=2350 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-3cda24612d85b775aec3c44252a85e8c_l3.png "Rendered by QuickLaTeX.com")
- An electrical engineer supervises the production of three types of electrical components. Three kinds of material: metal, plastic, and rubber are required for production. The amounts needed to produce one unit of component 1 are 15 g of metal, 0.25 g of plastic, and 1.0 g of rubber. The amounts needed to produce one unit of component 2 are 17g of metal, 0.33g of plastic, and 1.2g of rubber. The amounts needed to produce one unit of component 3 are 19 g of metal, 0.42 g of plastic, and 1.6 g of rubber. If a total of 2.12, 0.0434, and 0.164 kg of metal, plastic, and rubber, respectively, are available each day. How many units of each component on average can be produced every day?
- Use the Gauss-Jordan elimination method to solve the following linear system of equations:
![\[ \begin{split} 120x_1-40x_2=637.65\\ -40x_1+110x_2-70x_3=735.75\\ -70x_2+170x_3-100x_4=588.60\\ -100x_3+120x_4-20x_5=735.75\\ -20x_4+20x_5=882.90 \end{split} \]](https://engcourses-uofa.ca/wp-content/ql-cache/quicklatex.com-935dc4801632ceaa6a01aae0ef5eee12_l3.png "Rendered by QuickLaTeX.com")